[TIL/정처기] 2025/03/11
20년~24년, 5년간 출제되었던 모든 코드 + 이론 문제 핵심 포인트 300선을 총 15회에 걸쳐 정리할 예정입니다. 요긴하게 활용하십시오. 아 그리고 코드 공부할 때 다음 사이트에서 실행 순서를 확인해보세요. 많은 도움이 될 것입니다. C, JAVA, Python
20년~24년, 5년간 출제되었던 모든 코드 + 이론 문제 핵심 포인트 300선을 총 15회에 걸쳐 정리할 예정입니다. 요긴하게 활용하십시오.
아! 그리고 코드 공부할 때 다음 사이트에서 실행 순서를 확인해 보세요. 많은 도움이 될 것입니다. C, JAVA, Python, C++, JS 디버깅 가능합니다. Claude에게 질문하고자 하는 코드의 본질이 무엇인지 물어보고, 동시에 해당 사이트에서 실행 순서를 확인하면 대부분 다 이해될 것입니당.
https://pythontutor.com/
24년 3회 기출 코드 정리 ✍️
24-3-1-JAVA ⚙️
public class Main {
static String[] x = new String[3];
static void func(String[] x, int y){
for(int i = 1; i < y; i++){
if(x[i-1].equals(x[i])){
System.out.print("O");
}
else{
System.out.print("N");
}
}
for(String z : x){
System.out.print(z);
}
}
public static void main(String[] args){
x[0] = "A";
x[1] = "A";
x[2] = new String("A");
func(x,3);
}
}x[2]는 ``new 키워드`를 통해 새로운 메모리 주소에 할당된다. `equals()` 메소드는 `문자열의 내용(값)`을 비교하고 `== 연산자`는 `객체의 참조(메모리 주소)``를 비교한다는 개념을 알고 있는지를 물어보는 코드. 출력 결과는 "OOAAA".
24-3-2-Python ⚙️
def func(lst):
for i in range(len(lst)//2):
lst[i], lst[-i-1] = lst[-i-1], lst[i]
lst = [1,2,3,4,5,6]
func(lst)
print(sum(lst[::2])-sum(lst[1::2]))
리스트 대칭 교환 상황을 인지할 수 있는지, 해당 결과물을 토대로 슬라이싱을 할 수 있는지 물어보는 코드. 출력 결과는 3.
**24-3-6-C ⚙️**#include
int func(){ static int x = 0; x+=2; return x; }
int main(){ int x = 0; int sum = 0; for(int i = 0; i < 4; i++){ x++; sum += func(); } printf("%d", sum); return 0; }

main 함수에서의 ```지역 변수 x```와, func() 내부의 ```static x```는 별개라는 사실을 알아야 하고, 코드의 흐름대로 변수들의 변화를 표의 형태로 정리할 수 있어야 한다. 출력 결과는 20.
**24-3-10-C ⚙️**
#include
struct Node { int value; struct Node next; };
void func(struct Node node){ while(node != NULL && node -> next != NULL){ int t = node -> value; node -> value = node -> next -> value; node -> next -> value = t; node = node -> next -> next; } }
int main(){ struct Node n1 = {1, NULL}; struct Node n2 = {2, NULL}; struct Node n3 = {3, NULL};
n1.next = &n3; n3.next = &n2; func(&n1); struct Node current = &n1; while(current != NULL){ printf("%d", current -> value); current = current -> next; } return 0; }
Node 구조체는 정수 값(value)과 다음 노드를 가리키는 포인터(next)로 구성되어 있다. ```연결 리스트에서 인접 노드의 값만 교환하는 기법```을 테스트한다. 노드는 n1→n3→n2 순서로 연결되어 있으며, func 함수는 현재 노드와 다음 노드의 값을 교환한 후 두 칸씩 건너뛰며 진행한다. 처음 n1과 n3의 값만 교환되고 n2는 변경되지 않아 출력 결과는 312가 된다.
**24-3-12-Python ⚙️**
def func(value): if type(value) == type(100): return 100 elif type(value) == type(""): return len(value) else: return 20
a = "100.0" b = 100.0 c = (100, 200)
print(func(a)+func(b)+func(c))
24-3-14-JAVA ⚙️
public class Main {
public static void main(String[] args) {
B a = new D();
D b = new D();
System.out.print(a.getX()+a.x+b.getX()+b.x);
}
}
class B {
int x = 3;
int getX(){
return x*2;
}
}
class D extends B {
int x = 7;
int getX(){
return x*3;
}
}B a = new D(); - D 클래스의 객체 생성 후 B 타입 변수 a에 할당 D b = new D(); - D 클래스의 객체 생성 후 D 타입 변수 b에 할당
a.getX()의 경우, a는 B 타입으로 선언되었지만 실제 객체는 D 타입이기에 21을 반환한다. 이어서 변수는 참조 변수의 타입에 의해 결정되기에 a.x는 B 클래스의 x 변수에 접근하게 되어 3을 반환한다. b.getX()는 D 타입이므로 21을 반환한다. 마지막으로 b.x는 D 타입으로 선언되었기에 7을 반환한다. 출력 결과는 52.
**24-3-17-JAVA ⚙️**
public class Main { public static void main(String[] args) { int sum = 0; try{ func(); } catch(NullPointerException e){ sum = sum + 1; } catch(Exception e){ sum = sum + 10; } finally{ sum = sum + 100; } System.out.print(sum); } static void func() throws Exception { throw new NullPointerException(); } }
NullPointerException이 먼저 처리되며, finally 블록은 예외 처리 여부와 관계없이 항상 실행된다는 점을 인지해야 한다.
24-3-18-JAVA ⚙️
class Printer {
void print(Integer a){
System.out.print("A" + a);
}
void print(Object a){
System.out.print("B" + a);
}
void print(Number a){
System.out.print("C" + a);
}
}
public class Main {
public static void main(String[] args) {
new Collection<>(0).print();
}
public static class Collection<T> {
T value;
public Collection(T t) {
value = t;
}
public void print() {
new Printer().print(value);
}
}
}0을 전달했는데 출력 결과가 B0라는 것은, Printer 클래스로 전달된 0의 타입이 Object라는 것이다.
0을 전달했으면 Integer이기에, A0가 출력되어야 할 것 같은 생각이 든다. 다만 제너릭 자료형 T가 Integer로 결정되는 것은 컴파일 과정에서만 유효한 것이고 실행 과정에서는 기본 자료형인 Object로 취급된다.
24-3-19-C ⚙️
#include <stdio.h>
void func(int** arr, int size){
for(int i = 0; i < size; i++){
*(*arr + i) = (*(*arr + i) + i) % size;
}
}
int main(){
int arr[] = {3,1,4,1,5};
int* p = arr;
int** pp = &p;
int num = 6;
func(pp, 5);
num = arr[2];
printf("%d", num);
return 0;
}이중 포인터를 통한 배열 조작이 핵심인 코드라고 할 수 있다. 포인터 산술 연산과 역참조를 통해 배열 요소에 접근하고, ``(원래 값 + 인덱스) % size`` 연산을 수행하게 된다.
이론 문제 포인트 20선 ✍️
1. 애자일 모형 ✅ - 고객의 요구사항에 유연하게 대응할 수 있도록 일정한 주기를 반복하면서 개발하는 모형 - ``스크럼, XP, 칸반, Lean, 기능 중심 개발(FDD)`` 등 개발 모형이 애자일 모형에 해당
2. XP의 주요 실천 방법 ✅ - ``Pair Programming``: 다른 사람과 함께 프로그래밍을 수행 - ``Collective Ownership``: 개발 코드에 대한 권한과 책임을 공동으로 소유 - ``Test-Driven Development``: 테스트 케이스 작성, 자동화된 테스팅 도구 사용 - ``Whole Team``: 모든 구성원은 각자 자신의 역할이 있고 그 역할에 대한 책임을 가져야 함 - ``Continuous Integration``: 모듈 단위로 나눠서 개발된 코드들은 하나의 작업이 마무리될 때마다 지속적으로 통합됨 - ``Refactoring``: 프로그램 기능의 변경 없이 시스템을 재구성 - ``Small Releases``: 릴리즈 기간을 짧게 반복, 고객의 요구사항에 신속히 대응
3. 기능 요구사항 ✅ - 시스템의 I/O로 무엇이 포함되어야 하는지 - 시스템이 어떤 데이터를 저장하거나 연산을 수행해야 하는지 - 시스템이 반드시 수행해야 하는 기능 - 사용자가 시스템을 통해 제공받기를 원하는 기능
4. 비기능 요구사항 ✅ - 품질이나 제약사항과 관련된 요구사항 - 시스템 장비 구성 요구사항 - 성능 요구사항 - 인터페이스 요구사항 - 데이터를 구축하기 위해 필요한 요구사항 - 테스트 요구사항 - 보안 요구사항 - 품질 요구사항(가용성/정합성/상호 호환성/대응성/이식성/확장성/보안성 등)
5. 자료 흐름도 구성 요소 ✅ - ``프로세스(Process)``: 원 - ``자료 흐름(Data Flow)``: 화살표 - ``자료 저장소(Data Store)``: 평행선 - ``단말(Terminator)``: 사각형
6. 연관 관계 ✅ - Association, 2개 이상의 사물이 서로 관련되어 있는 관계 - 타이어/바퀴/엔진 => 차
7. 집합 관계 ✅ - Aggregation, 하나의 사물이 다른 사물에 포함되어 있는 관계 - 컴퓨터 - 프린터
8. 일반화 관계 ✅ - Generalization, 하나의 사물이 다른 사물에 비해 더 일반적이거나 구체적인 관계 - 버스/택시/승용차 => 차
9. 의존 관계 ✅ - 필요에 의해 서로에게 영향을 주는 짧은 시간 동안만 연관을 유지하는 관계 - TV-리모콘 / 할인율-등급
10. 클래스 다이어그램 ✅ - 클래스와 클래스가 가지는 속성, 클래스 사이의 관계를 표현
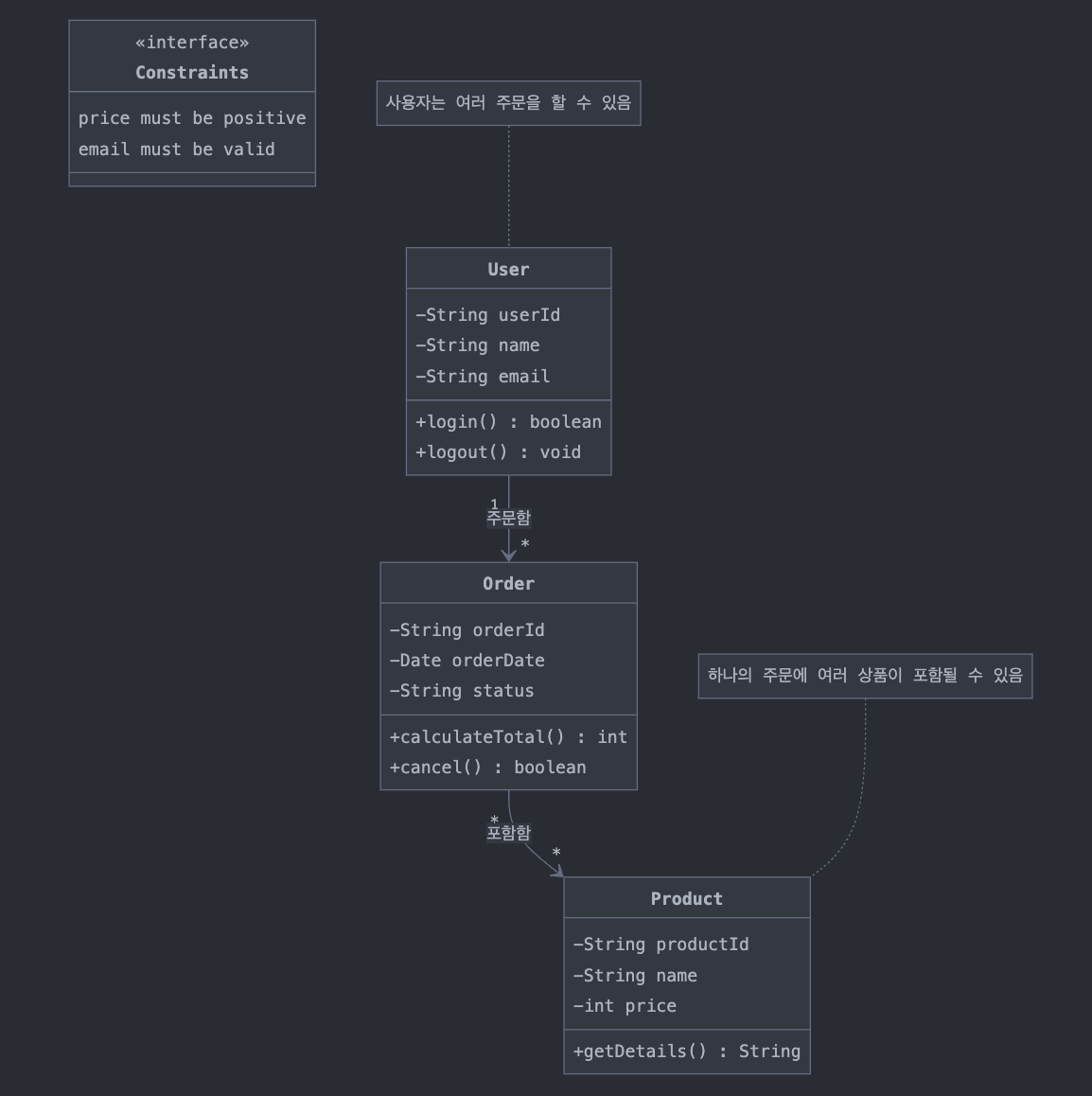
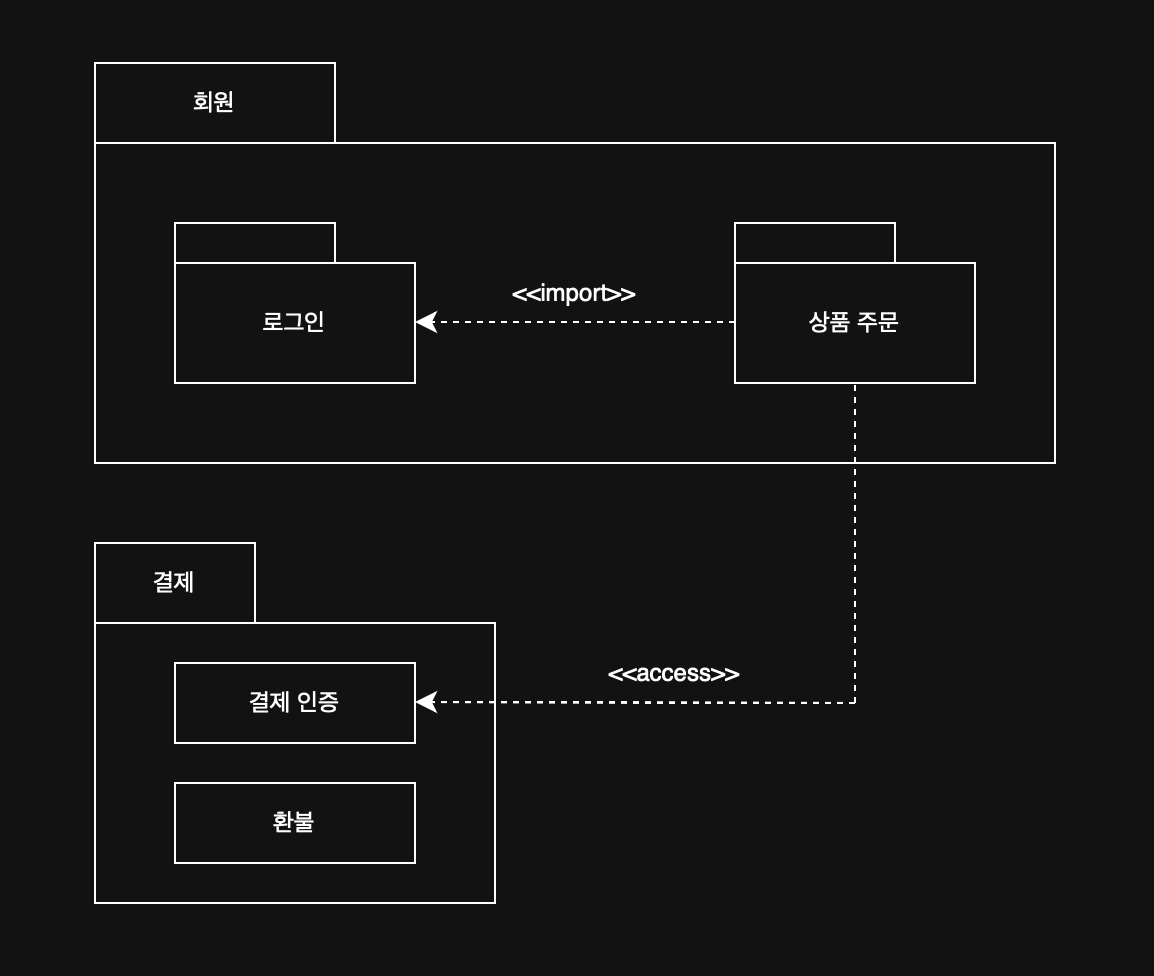
11. 패키지 다이어그램 ✅ - 유스케이스나 클래스 등의 요소들을 그룹화한 패키지 간의 의존 관계를 표현한 것
12. LOC 기법 ✅ - 소프트웨어 각 기능의 원시 코드 라인 수 의 비관치/낙관치/기대치를 측정하여 예측치를 구하고 이를 이용하여 비용을 산정하는 기법 - 노력(인월) = 개발 기간 X 투입 인원 = LOC/1인당 월평균 생산 코드 라인 수 - 개발 비용 = 노력(인월) X 단위 비용(1인당 월평균 인건비) - 개발 기간 = 노력(인월)/투입 인원 - 생산성 = LOC/노력(인월)
13. 데이터베이스 설계 순서 ✅ - ``요구 조건 분석``: 요구 조건 명세서 작성 - ``개념적 설계``: 개념 스키마, 트랜잭션 모델링, E-R 모델 - ``논리적 설계``: 논리 스키마, 트랜잭션 인터페이스 설계 - ``물리적 설계``: 물리적 구조의 데이터로 변환 - ``구현``: DDL로 데이터베이스 생성, 트랜잭션 작성
14. 개념적 설계 ✅ - 정보 모델링 - 현실 세계에 대한 인식을 추상적 개념으로 표현하는 과정
15. 논리적 설계 ✅ - 데이터 모델링 - 현실 세계에서 발생하는 자료를, 특정 DBMS가 지원하는 논리적 자료 구조로 변환(mapping)시키는 과정
16. 물리적 설계 ✅ - 데이터 구조화 - 논리적 설계에서 논리적 구조로 표현된 데이터를 물리적 구조의 데이터로 변환하는 과정
17. 데이터 모델 ✅ - 현실 세계의 정보들을 컴퓨터에 표현하기 위해 단순화, 추상화하여 체계적으로 표현한 개념적 모형 - ``구조(Structure)`` - ``연산(Operation)`` - ``제약 조건(Constraint)``
18. 관계형 데이터베이스의 릴레이션 구조 ✅
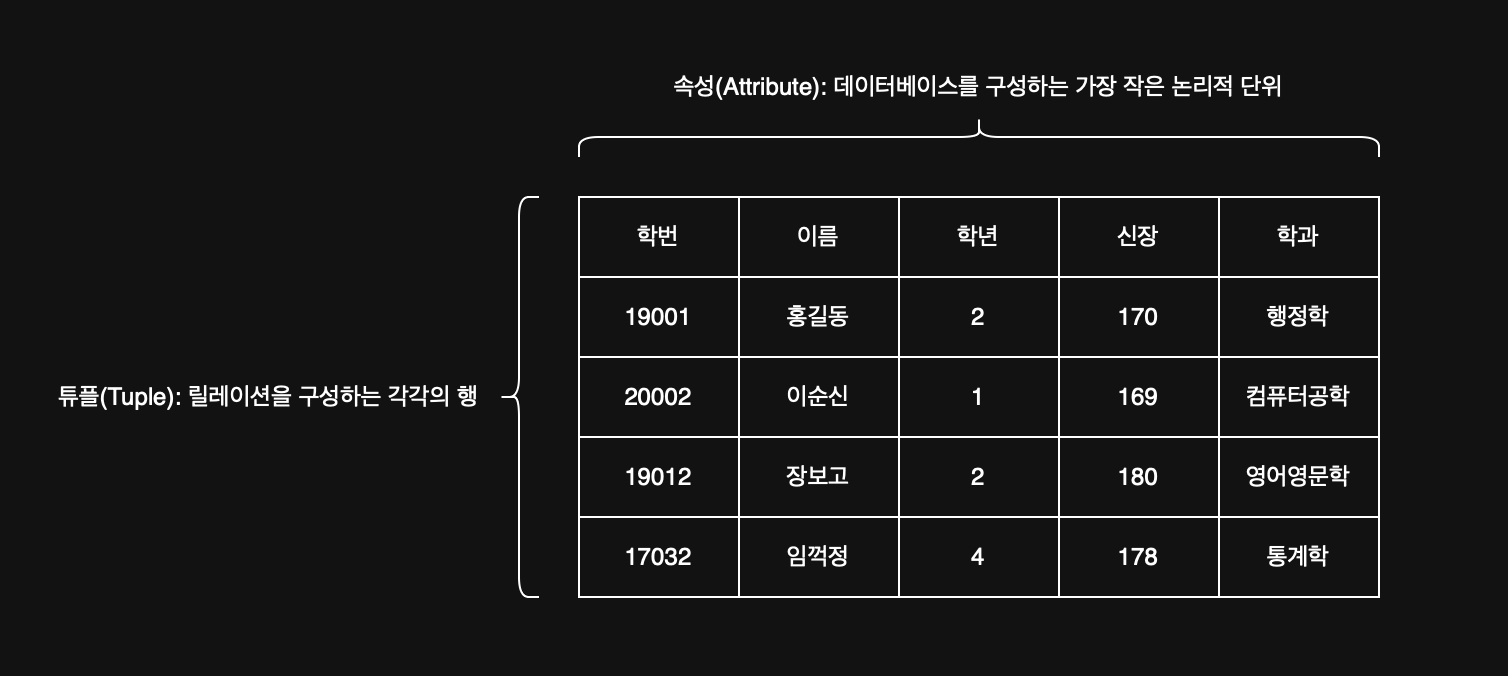
19. 튜플 ✅ - 릴레이션을 구성하는 각각의 행 - 튜플은 속성의 모임으로 구성 - 파일 구조에서 레코드와 같은 의미 - 튜플의 수를 ``카디널리티(Cardinality)`` 또는 기수, 대응수라고 함
20. 속성 ✅ - 데이터베이스를 구성하는 가장 작은 논리적 단위 - 파일 구조상의 데이터 항목 또는 데이터 필드에 해당 - 속성은 개체의 특성을 기술함 - 속성의 수를 ``디그리(Degree)`` 또는 차수라고 함
More to read
프론트엔드와 백엔드 사이
HTTP 상태 코드는 프론트엔드에서 백엔드로 보냈던 요청의 수행 결과를 의미하는 일종의 약속이며, API를 구성하는 핵심 요소 중 하나입니다. 상태 코드와 관련하여, 백엔드는 잘 모르는 프론트엔드의 슬픈 사정이 있습니다.아래는 요청이 실패했음에도, 백엔드에서 상태 코드
JWT토큰 관리 방식 톺아보기
0. 들어가며 🎯 서비스에 접근하려는 사용자가 누구인지 확인하는 과정을 사용자 인증이라고 합니다. 인증된 사용자에게 주어진 권한을 확인하는 작업은 인가라고 부릅니다. 이번 글에서는 인가는 다루지 않습니다. 사용자 인증에는 많은 방식이 있지만, 오늘은 세션 인증 방
A2AA2A / MCP 멀티 에이전트 오케스트레이션
0. 들어가며 ✍️ Google for Developers에, 레스토랑 공급망 시나리오로 엮은 6대 프로토콜(MCP, A2A, UCP, AP2, A2UI, AG-UI)에 대한 가이드가 게시된 이후, MCP와 A2A부터 구현해 보는 것이 좋을 것 같다는 생각이 들었습니