[TIL/React] 2024/12/26
reference: 1)https://bbangson.tistory.com/87 2)https://namhyo00.tistory.com/70#%EB%8F%99%EC%9E%91%EC%9B%90%EB%A6%AC 3)https://www.youtube.com/watch?v=
브라우저와 렌더링 🌐
1. 웹 브라우저의 동작 방식 🚀
1-1. 웹 브라우저의 기본 구조 ⚙️
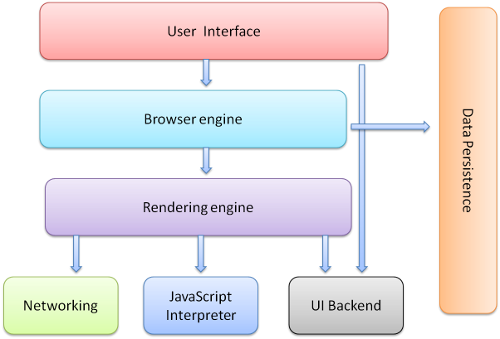
웹 브라우저는 ``사용자 인터페이스, 브라우저 엔진, 렌더링 엔진, 네트워킹, Javascript 인터프리터, UI 백엔드, 데이터 저장소`로 구성된다. 이번 글에서는 `네트워킹과 렌더링 엔진``에 대한 설명으로 논리를 전개해 나가고자 한다. 다음은 구성 요소에 대한 간단한 설명이다.
1. 사용자 인터페이스 (User Interface) - 역할: 사용자가 직접 상호작용하는 브라우저의 화면 부분. - 예시: 주소창, 뒤로가기/앞으로가기 버튼, 북마크, 스크롤바 등.
2. 브라우저 엔진 (Browser Engine) - 역할: 사용자 인터페이스와 렌더링 엔진 간의 다리 역할. - 설명: 사용자 명령(예: 웹페이지 열기)을 렌더링 엔진으로 전달하고, 결과를 사용자 인터페이스에 반영.
3. 렌더링 엔진 (Rendering Engine) - 역할: HTML, CSS를 해석하고 웹페이지를 화면에 렌더링. - 예시: 크롬(Chromium)의 Blink, 파이어폭스(Firefox)의 Gecko.
4. 네트워킹 (Networking) - 역할: HTTP/HTTPS를 사용해 서버와 통신하여 웹페이지 데이터를 가져옴. - 설명: 캐싱, 프록시 설정, 데이터 압축 등을 처리하여 네트워크 효율을 극대화.
5. JavaScript 인터프리터 (JavaScript Interpreter) - 역할: JavaScript 코드를 실행하고, 동적인 페이지 동작을 처리. - 예시: 크롬의 V8 엔진, 파이어폭스의 SpiderMonkey.
6. UI 백엔드 (UI Backend) - 역할: 브라우저의 UI 컴포넌트를 그리는 데 사용. - 설명: 스크롤바, 버튼 같은 기본 UI 요소를 렌더링.
7. 데이터 저장소 (Data Storage) - 역할: 데이터를 로컬에 저장하는 데 사용. - 예시: 쿠키, 로컬 스토리지, 세션 스토리지, IndexedDB, 캐시 스토리지.
1-2. 웹 브라우저의 동작 원리 ⚙️
후술하겠지만, 렌더링 엔진은 말 그대로 화면을 그리는 역할을 한다. 그런데 화면을 그리기 이전에 뭔가 리소스를 주고받는 흐름이 필요하지 않을까? 해당 과정은 Networking 프로세스에서 처리되고, 핵심은 DNS다.
DNS는 Domain Name System의 약자다.
누군가가 크롬 브라우저를 오픈한 뒤, 위와 같은 url을 입력했다고 가정하자. 겉으로 볼 때에는 마술처럼 해당 도메인 화면이 뚝딱 나오는데, 실제로 내부 동작은 굉장히 복잡하다.
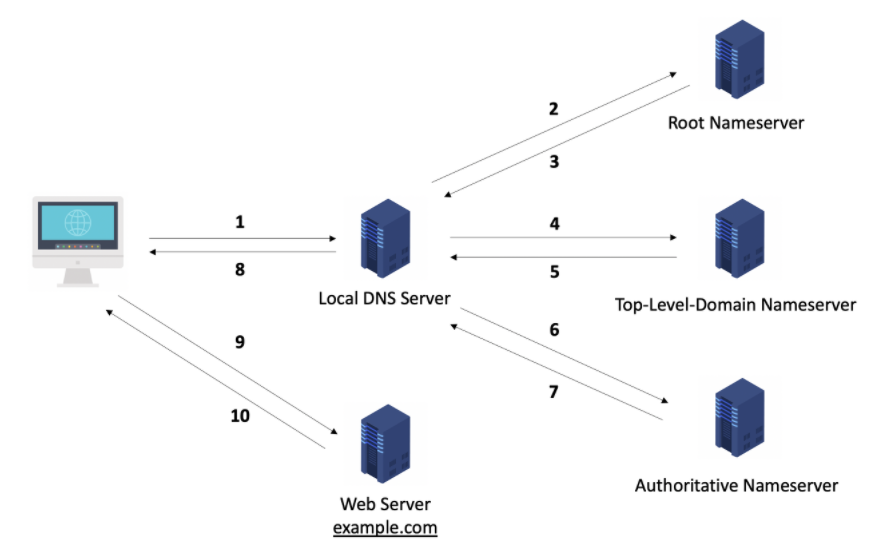
<1번 과정> 사용자가 브라우저에서 www.example.com을 주소창에 입력하는 행위가 먼저 이루어진다. 해당 요청은 가정 먼저 로컬 DNS 서버로 전달된다. 이때, 로컬 DNS 서버가 요청된 도메인, 즉 www.example.com의 IP 주소를 이미 가지고 있을 수 있다. 이것을 "캐싱되어 있다"라고 표현한다. 캐싱된 데이터가 있다면 바로 응답하고, 캐싱된 데이터가 없다면 Root 네임 서버로 요청을 전달한다.
<2번 과정> 로컬 DNS 서버는 Root 네임 서버로 요청을 보낸다.
<3번 과정> Root 네임 서버는 요청에 대해 해당 도메인의 최상위 도메인, 즉 Top-Level-Domain인 .com을 담당하는 네임 서버의 IP 주소를 반환한다.
<4번 과정> 로컬 DNS 서버는 Root 네임서버가 반환한 TLD 네임서버(.com)로 요청을 보낸다.
<5번 과정> TLD 네임서버는 example.com 도메인을 담당하는 Authoritative Nameserver의 주소를 반환한다.
<6번 과정> 로컬 DNS 서버는 Authoritative Nameserver로 요청을 전달한다.
<7번 과정> Authoritative Nameserver는 요청에 대한 실제 IP 주소를 로컬 DNS 서버로 반환한다.
<8번 과정> 로컬 DNS 서버는 전달받은 IP 주소를 사용자의 컴퓨터에 반환한다.
<9번 과정> 사용자의 브라우저는 실제 IP 주소를 활용하여, 실제 웹 서버(example.com)와 연결을 시도하게 된다.
<10번 과정> 웹 서버는 사용자의 요청에 대한 응답(HTML, CSS, 이미지 파일 등)을 반환하게 되고, 이후 렌더링 엔진에 의해 화면을 그리게 된다.
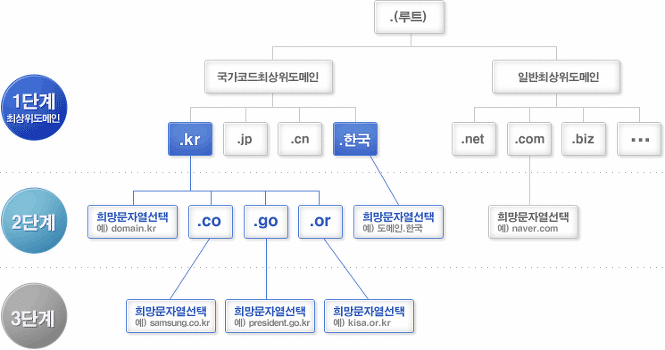
도메인의 루트부터 서브까지 계층적으로 탐색을 이어나간다고 이해하면 된다. url 기준으로 파악하면, 탐색을 가장 뒷부분부터 진행한다고 볼 수도 있다.
2. 브라우저 렌더링 프로세스 🚀
앞에서는 과정을 순서대로 나타냈을 뿐이라, 이해가 되지 않았을 수 있다. 핵심은, 사람이 기억하기 쉬운 도메인(www.naver.com)이 있고 그 도메인에 해당하는 실제 IP 주소가 있는 DNS 서버라는 것이 있다는 점이다.
원민관이라는 사람의 전화번호가 저장된 전화번호부가 있고, 우리는 원민관 하단에 위치한 수화기 버튼만 클릭하면 실제 번호(010-7xxx-xxxx)로 전화가 연결되는 것과 같은 이치다. 번호를 하나하나 외우고 있는 것은 비효율적이기에 자연스럽게 DNS와 같은 시스템 내지는 프로세스가 나오게 된 것으로 이해하면 된다.
그런데 위 10단계 과정에서 우리가 궁극적으로 원했던 return 값이 무엇이었는지를 다시 생각해 보자. 우리는 어쨌는 도메인을 주소창에 입력했을 때, 해당하는 화면을 보고 싶은 것이다. 그래서 최종적으로 HTML, CSS, 이미지 파일 등을 받아왔다. 이제 받아온 재료를 브라우저가 어떻게 그려내는지를 알아보면 된다.
2-1. Parsing이란? ⚙️
이 지점에서 Parsing(파싱)이라는 용어에 대해 정립하고 시작하는 것이 좋다. Computer Science에서 parsing이란 일련의 문자열을 토큰 단위로 분해하고 이들로 이루어진 파스 트리를 만드는 과정을 총칭한다. 이게 뭔 소리냐?

브라우저는 HTML을 최초로 받을 때 Bytes 형태로 받는다. Bits는 0 또는 1이다. 이러한 비트가 8개 모인 집합을 1바이트라고 한다. 텍스트 데이터는 보통 한 개의 텍스트가 1바이트로 구성된다. 만약 Hello라는 단어가 있다면, 이 단어는 5바이트이며 동시에 40비트라고 표현할 수 있다.

서버로부터 받은 Bytes 데이터를, 브라우저는 문자(character) 형태로 변환한다. 이러한 과정을 문자 인코딩(encoding)이라 부른다.

위에서 인코딩한 문자를 HTML 문서 규칙에 맞게 나누는 과정을 토큰화라고 하고, 나누어진 개별 요소를 Token(토큰)이라 부른다.
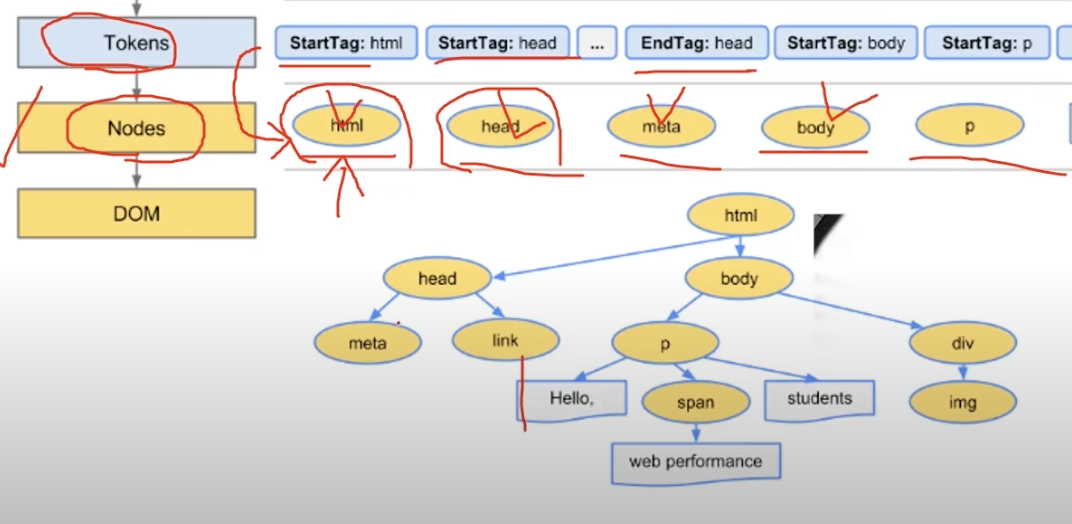
토큰이 트리 형태로 구성될 때, 트리의 기준에서 본 개별 요소를 Node(노드)라 한다. 파싱 단계에서의 최소 단위가 토큰이고, 노드는 최종적으로 문서 구조를 형성하는 DOM Tree의 구성 요소다. 귀에 걸면 귀걸이, 코에 걸면 코걸이 느낌으로 받아들이면 된다.
### 2-2. Critical Rendering Path ⚙️
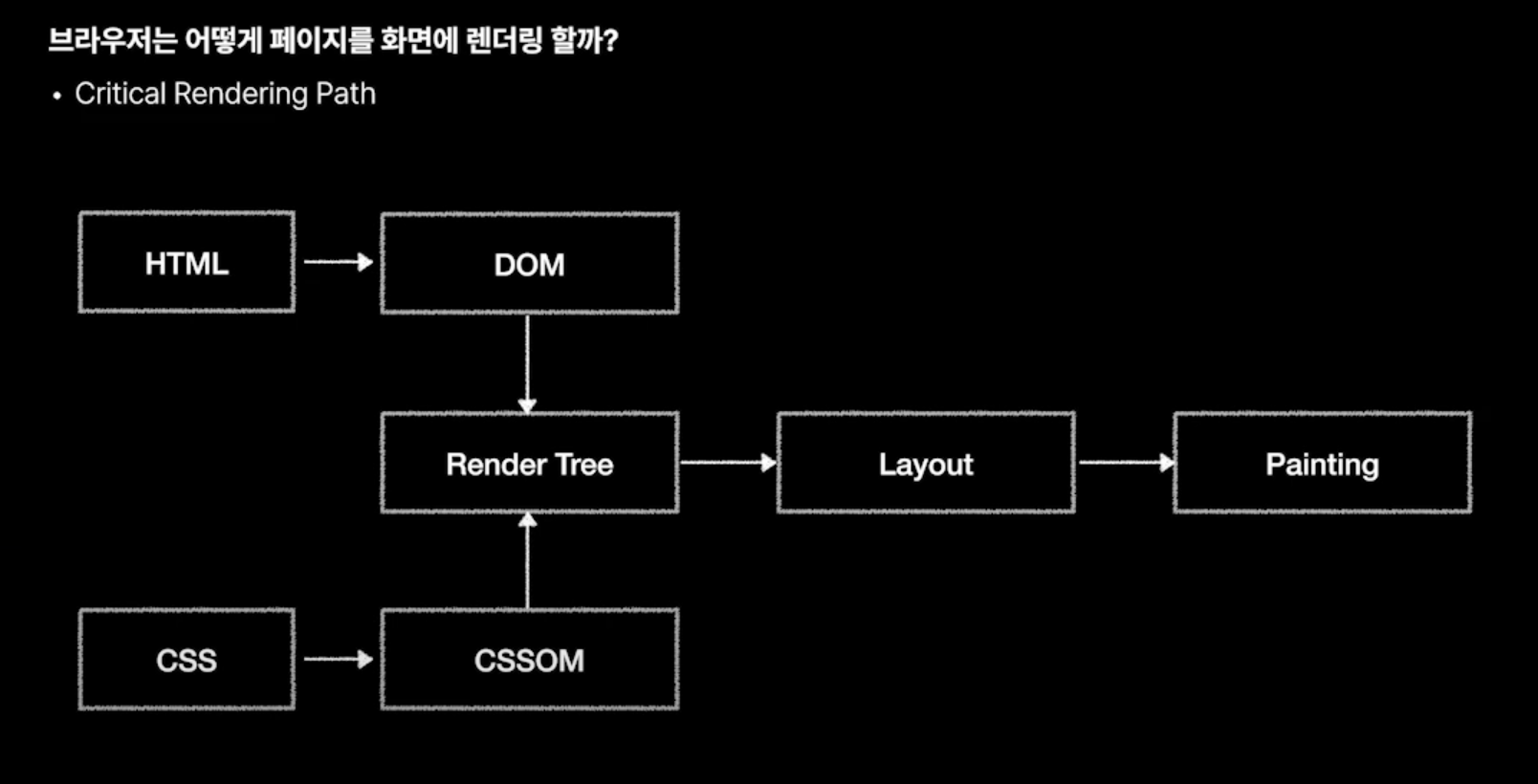
그렇다면 지금부터는 전문가처럼 말할 수 있다.
HTML이라는 재료를 Parsing하는 과정을 거쳐 DOM Tree를 구성하게 된다. DOM은 Document Object Model이다.
겁먹지 말자. 받아온 HTML 문서를 트리 구조로 만든 것이 DOM이다. 이게 트리지 ㅋㅋ 뭔 크리스마스여~
CSS도 이런 식의 트리 형태로 만든다. 그것이 바로 CSS Object Model, 즉 CSSOM이다.
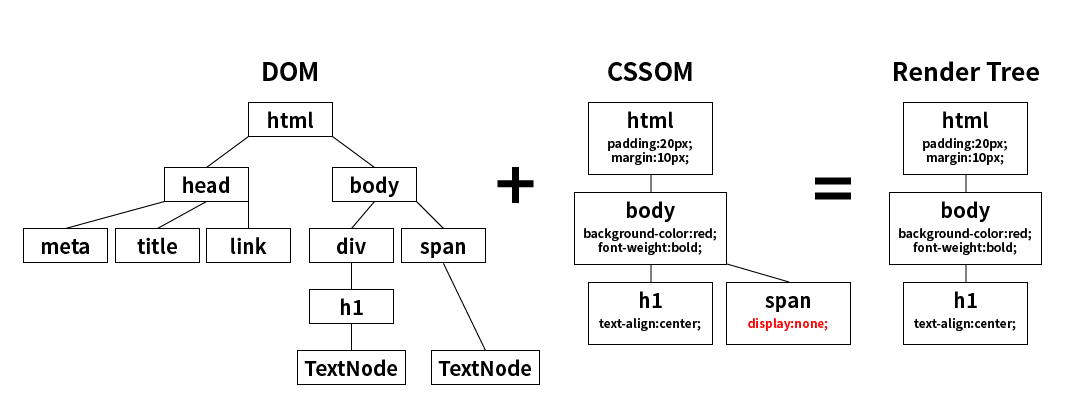
스타일링에 대한 내용이 담긴 문서를 트리 형태로 만든 것이다.
DOM Tree와 CSSOM Tree를 합친 형태를, Render Tree라고 부르기로 합의를 봤다.
이후 레이아웃 단계를 거친다. Render Tree를 기반으로 요소들의 크기와 위치를 계산하는 과정이다. 레이아웃 단계가 끝나면 페인팅 단계를 끝으로 렌더링을 마치게 된다. 페인팅은 레이아웃에서 계산된 요소들의 크기와 위치를 바탕으로 화면에 픽셀 단위로 렌더링 하는 과정을 의미한다.
DOM과 CSSOM을 통해 Render Tree를 만들고, Render Tree를 기반으로 Layout과 Painting을 수행하는 일련의 과정을 ```Critical Rendering Path```라고 부른다.
### 2-3. DOM이 updae되면? ⚙️
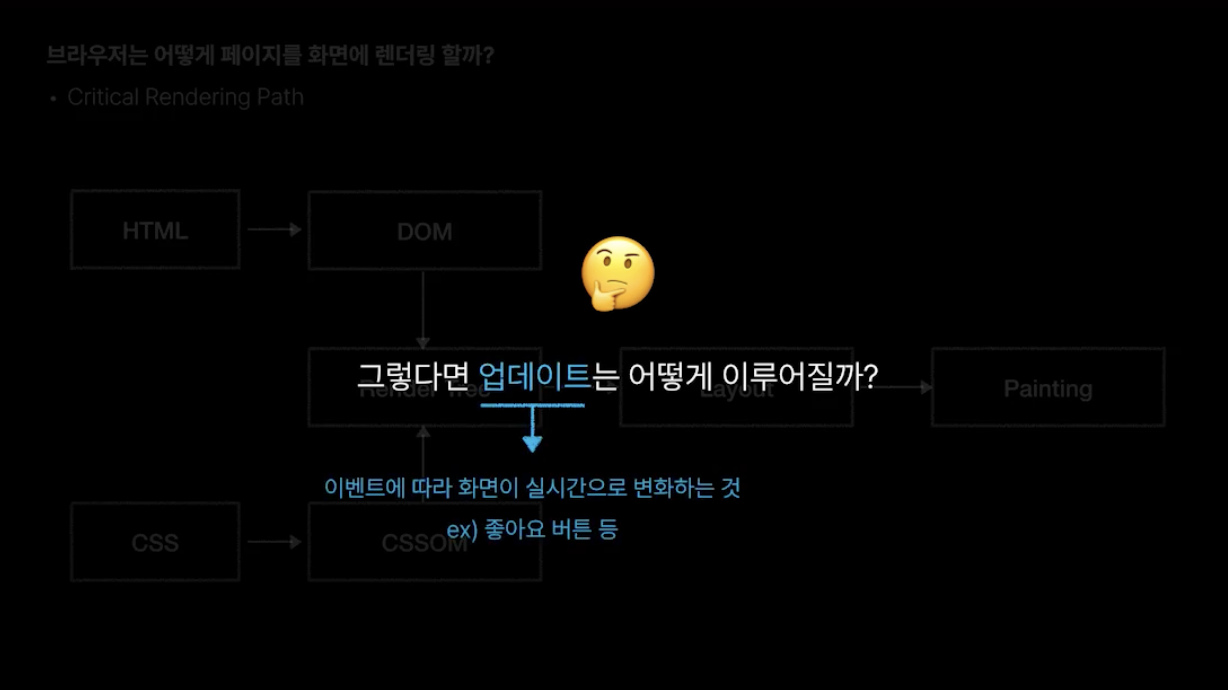
이 부분이 문제다. 좋아요 버튼을 클릭하면, 숫자가 늘어나든 하트에 색이 더해지든, DOM이 변화한다.
DOM이 수정되면 전체적인 Critical Rendering Path 과정을 다시 한번 겪어야 한다. 그 과정에서 layout을 다시 조정하는 것을 reflow, painting을 다시 하는 것을 repaint라 부른다.
reflow와 repaint는 굉장히 expensive한 과정이다. 개발에서 expensive는 연산이 굉장히 많이 필요함을 의미한다. 유저가 100만 명이고, 100만 명이 딱 한 번씩 좋아요를 누른다고 가정하면 ```reflow+repaint```라는 expensive한 과정이 100만 번 수행되어야 하는 것이다.
### 2-4. Javascript Update(defer/async) ⚙️
그런데 자바스크립트가 업데이트는, 자바스크립트 엔진에서 이루어지는 것이지 렌더링 엔진에서 이루어지는 것이 아니다.
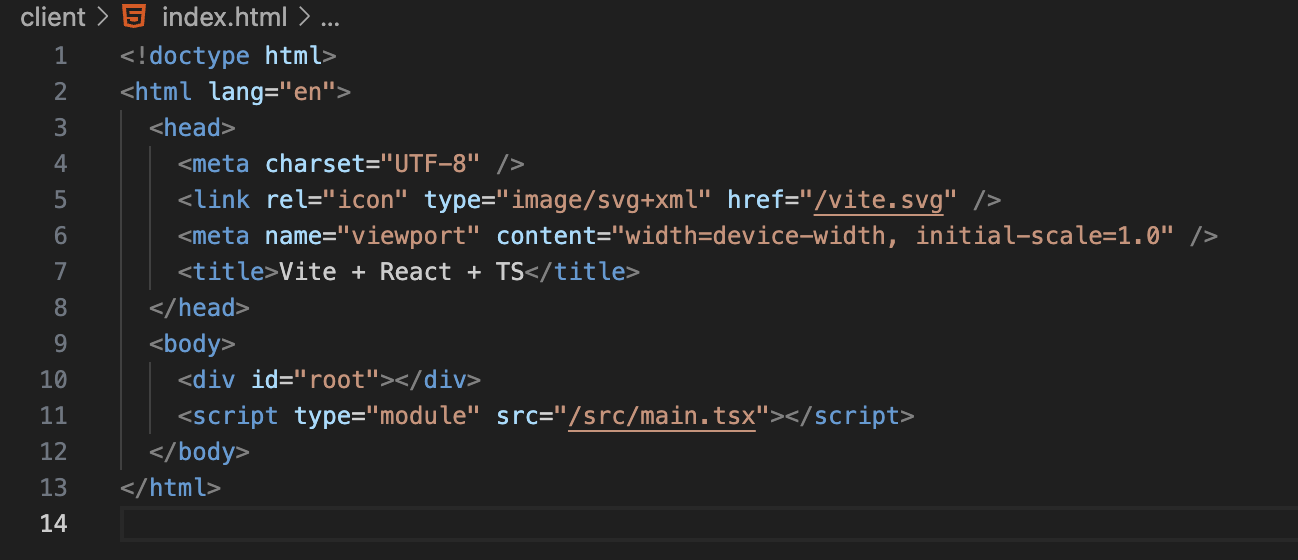
보통 html 파일은 위와 같이 구성된다. javascript 파일은 위 코드에서 script 태그의 src 속성에 할당되어 있다. script가 변경될 때, 해당 업데이트를 렌더링 엔진이 아니라 자바스크립트 엔진이 처리하는 것이다.
문제는 HTML을 파싱하는 파서는, script 태크를 만나면 Javascript 코드를 실행하기 위해 DOM 생성을 멈춘다. script 태그 내의 javascript 코드에 대한 로드 및 파싱이 먼저 이루어지고, 해당 작업이 끝나고 나면 다시 HTML 파서로 제어권이 넘어가서 중지했던 시점부터 DOM 생성을 재개하게 된다.
브라우저는 동기적으로 HTML, CSS, JS를 처리한다. 따라서 JS가, 완성되지 않은 DOM을 조작하게 될 경우 에러가 발생할 수 있다. 그래서 위 코드처럼 일반적으로 JS 코드를 body 태그 하단에 위치시킨다.
그런데 이것이(script를 하단에 배치하는 것이) 유일한 해결책은 아니다. 왜냐하면, HTML 문서 자체가 아주 클 경우, 브라우저가 HTML 문서 전체를 다운로드한 뒤 스크립트를 다운받게 하면 페이지가 굉장히 느려질 가능성이 높다.
#### 2-4-1. defer 🎨
script 태그에 defer 속성을 추가하면, 해당 스크립트는 '백그라운드'에서 다운로드 된다. 따라서 해당 script를 다운로드하는 도중에도 HTML 파싱이 멈추지 않게 된다.
...스크립트 앞 콘텐츠...
...스크립트 뒤 콘텐츠...
run: https://ko.javascript.info/script-async-defer
그런데 defer가 적용된 스크립트는 어쨌든 HTML 파싱이 끝난 후(DOM 생성이 완료된 후) 실행된다. 다만 스크립트 다운로드가 동시에 이루어지는 것이다.
주의할 점이 있다. 위 코드처럼 용량이 작은 script와 큰 script가 있을 경우, 파일 로드를 병렬적으로 처리하기에 small script가 먼저 로드될 수 있다. 하지만 defer 스크립트는 일반적인 스크립트와 마찬가지로 HTML에 명시적으로 추가된 순으로 실행된다. 따라서 항상 long 스크립트가 small 스크립트보다 먼저 실행된다. 추가적으로, defer 속성은 외부 스크립트에만 유효하다. script에 src가 없다면 defer 속성은 무시된다.
#### 2-4-2. async 🎨
async도 defer와 마찬가지로 백그라운드에서 다운로드된다. HTML 파싱을 멈추지 않는 것도 동일하다.
그러나, defer가 HTML 파싱을 마친 후 실행되는 것과 달리 async는 다운로드가 완료되면 HTML 파싱을 멈추고 즉시 실행된다. 따라서 HTML 파싱 흐름이 깨질 수 있다.
더 나아가 defer와는 달리 async 스크립트는 개별적으로 다운로드가 완료된 순서대로 실행된다. HTML에 명시적으로 작성된 순서와는 상관이 없다는 의미이다.
More to read
프론트엔드와 백엔드 사이
HTTP 상태 코드는 프론트엔드에서 백엔드로 보냈던 요청의 수행 결과를 의미하는 일종의 약속이며, API를 구성하는 핵심 요소 중 하나입니다. 상태 코드와 관련하여, 백엔드는 잘 모르는 프론트엔드의 슬픈 사정이 있습니다.아래는 요청이 실패했음에도, 백엔드에서 상태 코드
JWT토큰 관리 방식 톺아보기
0. 들어가며 🎯 서비스에 접근하려는 사용자가 누구인지 확인하는 과정을 사용자 인증이라고 합니다. 인증된 사용자에게 주어진 권한을 확인하는 작업은 인가라고 부릅니다. 이번 글에서는 인가는 다루지 않습니다. 사용자 인증에는 많은 방식이 있지만, 오늘은 세션 인증 방
A2AA2A / MCP 멀티 에이전트 오케스트레이션
0. 들어가며 ✍️ Google for Developers에, 레스토랑 공급망 시나리오로 엮은 6대 프로토콜(MCP, A2A, UCP, AP2, A2UI, AG-UI)에 대한 가이드가 게시된 이후, MCP와 A2A부터 구현해 보는 것이 좋을 것 같다는 생각이 들었습니