[TIL/혼공컴운] 2025/01/09
클라우드 환경에서 명령어 몇 줄로 애플리케이션 코드를 생성하고, AI로 "딸깍" 하면 view가 그려지는 오늘날. 너무 많은 것이 변할 때에는, 역설적으로 변하지 않는 본질에 집중하는 것이 더 유리한 전략일 수도 있다. 더욱이, 올해는 '개발 서적'을 될 수 있는 대로
1. Overview ✍️
클라우드 환경에서 명령어 몇 줄로 애플리케이션 코드를 생성하고, AI로 "딸깍" 하면 view가 그려지는 오늘날. 너무 많은 것이 변할 때에는, 역설적으로 변하지 않는 본질에 집중하는 것이 더 유리한 전략일 수도 있다. 더욱이, 올해는 '개발 서적'을 될 수 있는 대로 많이 읽는 것을 목표로 삼았다.
개발자 강민철 님의 저서 ``혼자 공부하는 컴퓨터구조+운영체제``를 읽고 정리하는 시간을 갖도록 하겠다. 총 500페이지 분량이고, 2~3일간 짬짬이 약 140페이지 정도를 읽었는데 글이 참 짜임새 있고 좋다는 느낌을 받았다.
2. 컴퓨터 구조 ✍️
2-1. 컴퓨터 구조를 학습하는 이유 🌿
개발자는 코드를 작성하는 사람'만'은 아니다. 코딩은 문제 해결의 수단일 뿐이므로, '코더'를 자처하는 일은 없어야겠다.
결국 문제는 컴퓨터 '안'에서 일어난다. 코드 몇 줄 디버깅하는 것도 문제이지만 그런 것은 약간의 성실함을 기반으로 구글링을 하거나, gpt에게 잘 정리해서 물어보면 금방 해결된다.
그런데 '컴퓨터 환경'에 관한 문제는, 관련하여 학습한 지식이 없다면 해결하려야 해결할 수가 없다.
하드웨어로서의 컴퓨터를 구입하는 것을 넘어서, AWS와 같은 클라우드 서비스를 이용할 때에도 CPU, 메모리, 저장용량 등의 개념이 포함된 인스턴스 유형을 본인이 직접 선별해야 하는데, 모르면 진행할 수가 없다.
말이 길었지만, 결국 문제 해결을 위해 컴퓨터 구조를 학습해야 한다는 것이다.
2-2. 컴퓨터 구조(정보/부품) 🌿
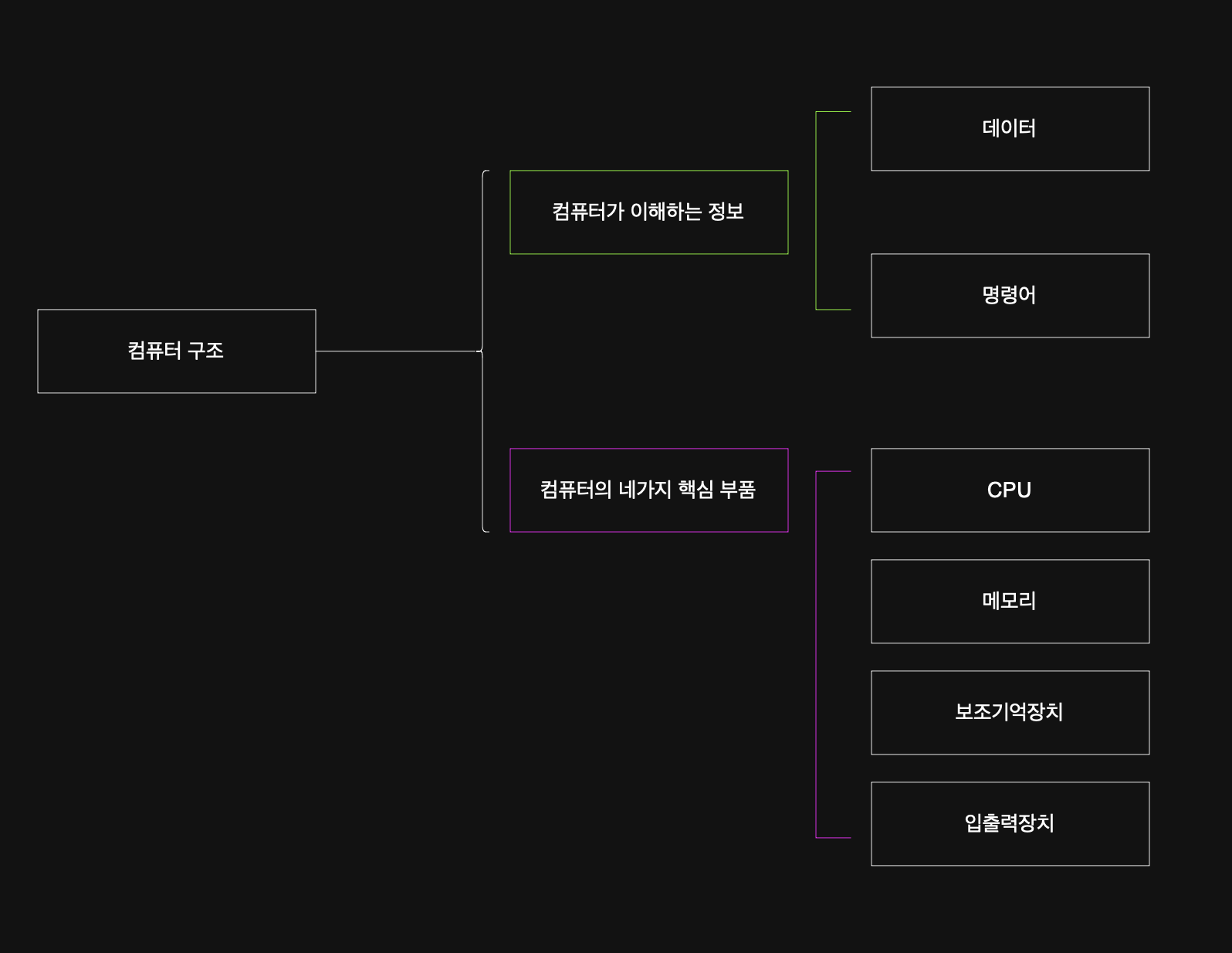
#### 2-2-1. 정보 ⚙️
컴퓨터는 0과 1로 표현된 정보만을 이해한다. 물론 양자 컴퓨터는 0과 1의 상태를 동시에 갖는 큐비트의 개념이 추가되어 동작하지만, 기본적인 컴퓨터는 0과 1을 이해한다.
0과 1의 조합이 ``데이터`로 표현되기도, `명령어``로 표현되기도 한다. 오늘은 데이터와 명령어, 즉 '컴퓨터가 이해하는 정보'에 관해 정리할 예정이다.
#### 2-2-2. 부품 ⚙️
하드웨어적 관점에서, 컴퓨터는 ``네 가지 핵심 부품(CPU, 메모리, 보조기억장치, 입출력장치)``로 구성된다.
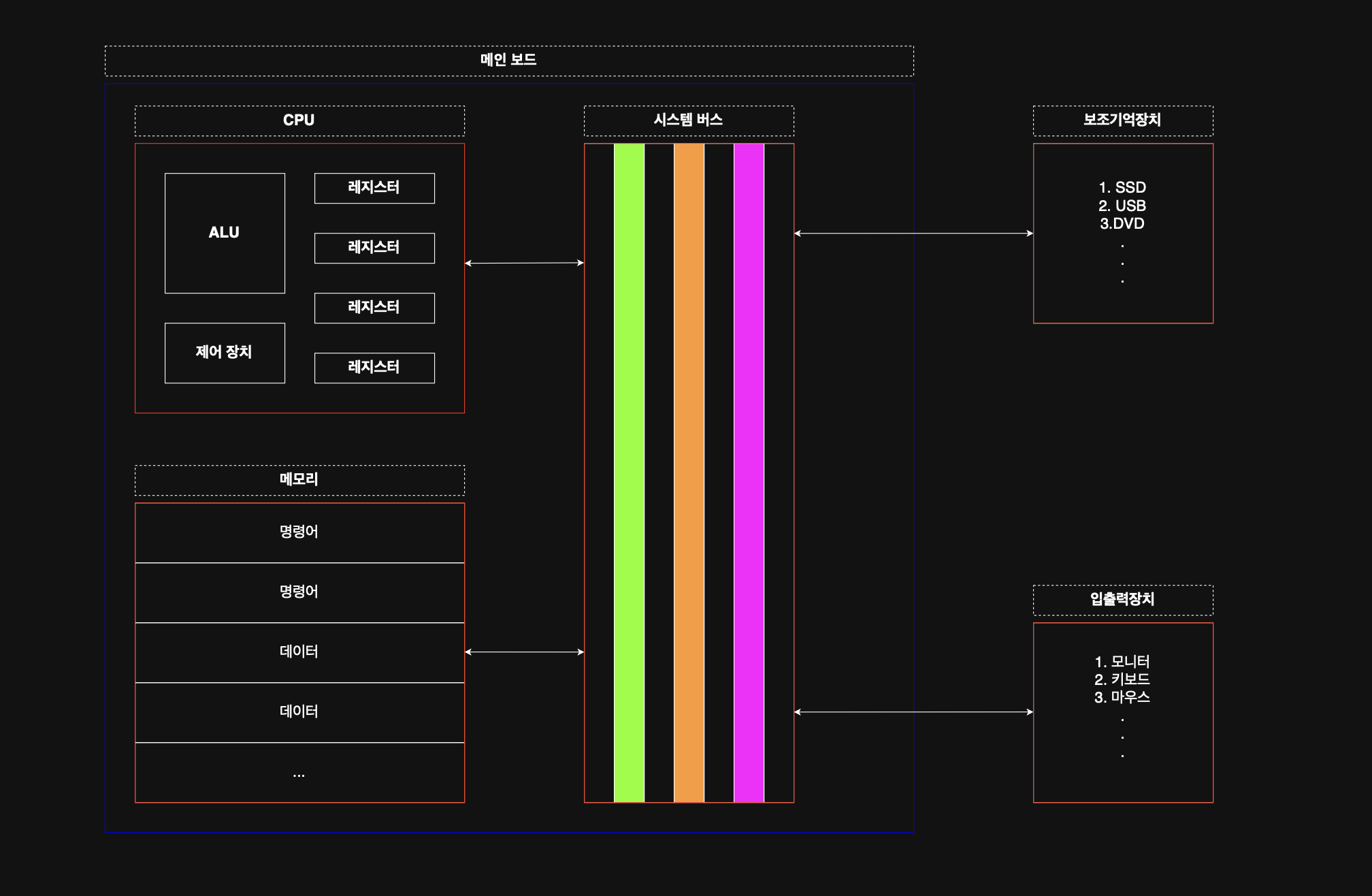
1. 주기억장치(메모리): 현재 실행되는 프로그램의 명령어와 데이터를 저장하는 부품
2. CPU: 메모리에 저장된 명령어를 읽고, 해석하고 실행하는 부품 2-1. ALU: CPU 내에서 실질적으로 연산을 수행하는 부품 2-2. 레지스터: CPU 내부의 작은 임시 저장 장치 2-3. 제어장치: 제어신호를 내보내고 명령어를 해석하는 장치
3. 보조기억장치: CPU가 실행할 프로그램이나 데이터를 영구적으로 저장할 수 있는 장치
4. 입출력장치: 컴퓨터 외부에 연결되어, 컴퓨터 내부와 정보를 교환하는 장치
5. 시스템버스(in 메인보드): 컴퓨터의 구성요소를 서로 연결하고 데이터 전달을 위한 통로
부품별로 시리즈가 연재될 예정이므로, 본 글에서는 전체적인 흐름을 파악하는 것을 목표로 했다.
3. 데이터 ✍️
3-1. 0과 1로 숫자 표현 🌿
#### 3-1-1. 정보 단위 ⚙️
전기의 흐름을 off와 on으로 나타낼 수 있다. 따라서 컴퓨터의 정보는 0과 1로 표현될 수 있다.
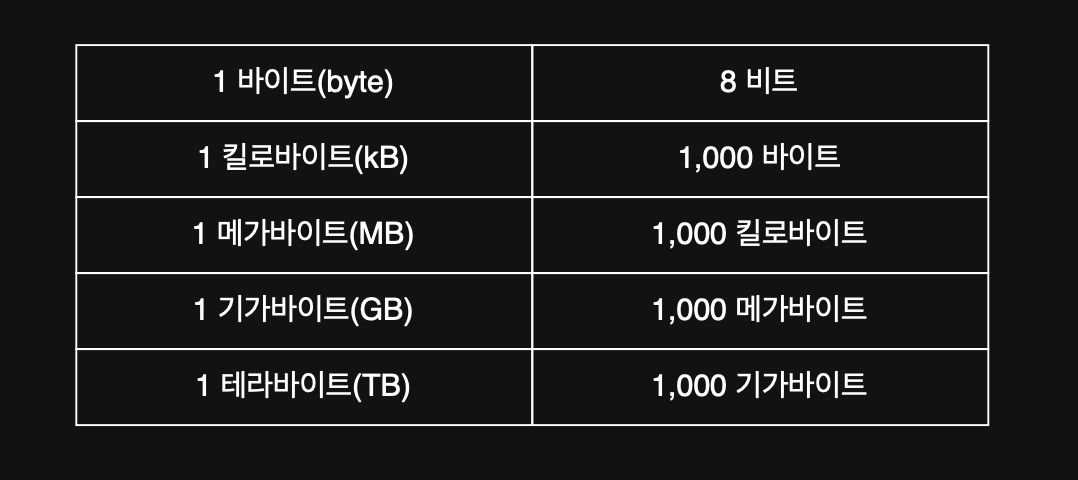
0과 1을 나타내는 가장 작은 정보 단위가 비트(bit)다. 1개의 비트가 2가지 케이스를 표현할 수 있다. 따라서 n비트는 2^n가지 정보를 표현할 수 있다.
표현의 편의를 위해 n개의 비트를 묶은 단위를 사용하곤 한다.
넘어가기에 앞서, 이진법과 십육진법 등의 변환 과정에 대해서는 깊게 설명하지 않으려 한다. 다만, 많은 도움을 받은 영상이 있어 해당 reference를 공유하는 것으로 설명을 갈음하겠다.
https://www.youtube.com/watch?v=Owz3RX7-sJk
#### 3-1-2. 이진법 ⚙️
우리는 보통 숫자를 셀 때 9를 넘어가는 시점에 자리 올림을 한다. 십진법(decimal)을 일상적으로 사용하기 때문이다.
이진법(binary)은 숫자가 1을 넘어가는 시점에 자리 올림을 수행하여, 0과 1로만 모든 숫자를 표현하는 방법을 뜻한다.
음수로 표현할 때에는, 2의 보수를 구해 해당 값을 음수로 간주한다. 0과 1을 전부 뒤집고 1을 더한 값이 2의 보수다.
1011(2)을 음수로 표현하면 0101(2)이 된다. 그런데 음수로서의 0101(2)인지, 십진수 5를 표현하기 위한 양수로서의 0101(2)인지 구분할 수 없다. 양수와 음수의 구분을 위해 플래그(flag)라는 개념을 사용하는데, 이는 향후 CPU 파트에서 깔끔하게 정리하도록 하겠다.
#### 3-1-3. 십육진법 ⚙️
그런데 이진법으로 32를 표현하려고 하면 100000(2)처럼 표현의 길이가 너무 길어진다. 십육진법(hexadecimal)은 이러한 문제를 해결하기 위해 사용하는 숫자 표현 방법이다.
수가 15를 넘어가는 순간 자리 올림을 수행한다.
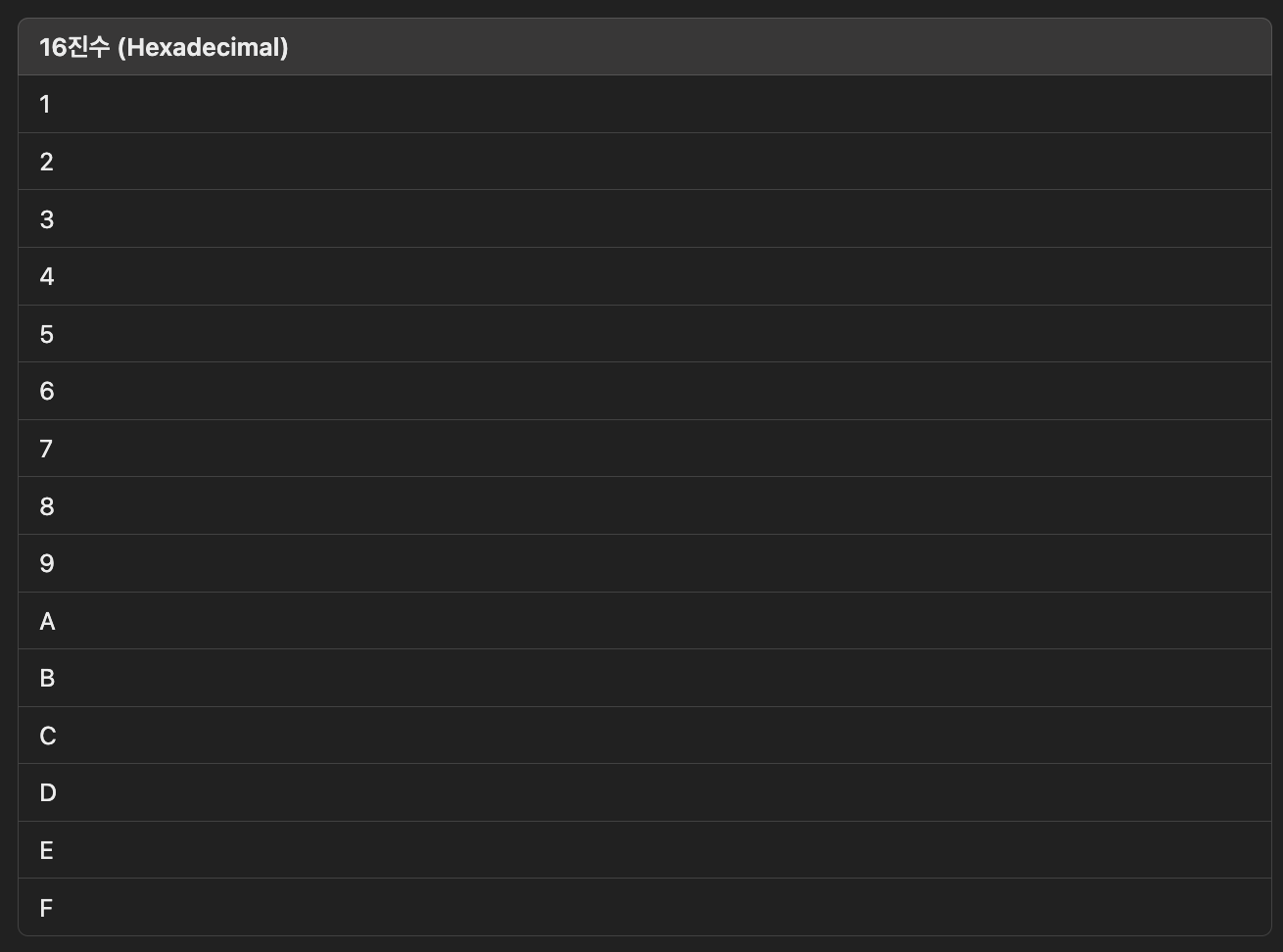
위 표는 각각 십진수 1~15에 대응되는 십육진수다.
3-2. 0과 1로 문자 표현 🌿
#### 3-2-1. 문자 집합 / 인코딩 / 디코딩 ⚙️
0과 1로 문자를 표현하려 할 때 알아야 할 세 가지 용어가 있다.
1. 문자 집합: 컴퓨터가 인식하고 표현할 수 있는 문자의 모음 2. 문자 인코딩: 문자를, 컴퓨터가 이해할 수 있는 0과 1 값으로 변환하는 과정 3. 문자 디코딩: 0과 1로 표현된 코드를, 사람이 읽을 수 있는 문자로 변환하는 과정
#### 3-2-2. 아스키 코드 ⚙️
아스키(American Standard Code for Information Interchange)는 초창기 문자 집합 중 하나로, 영어 알파벳과 아라비아 숫자, 그리고 일부 특수 문자를 포함한다.
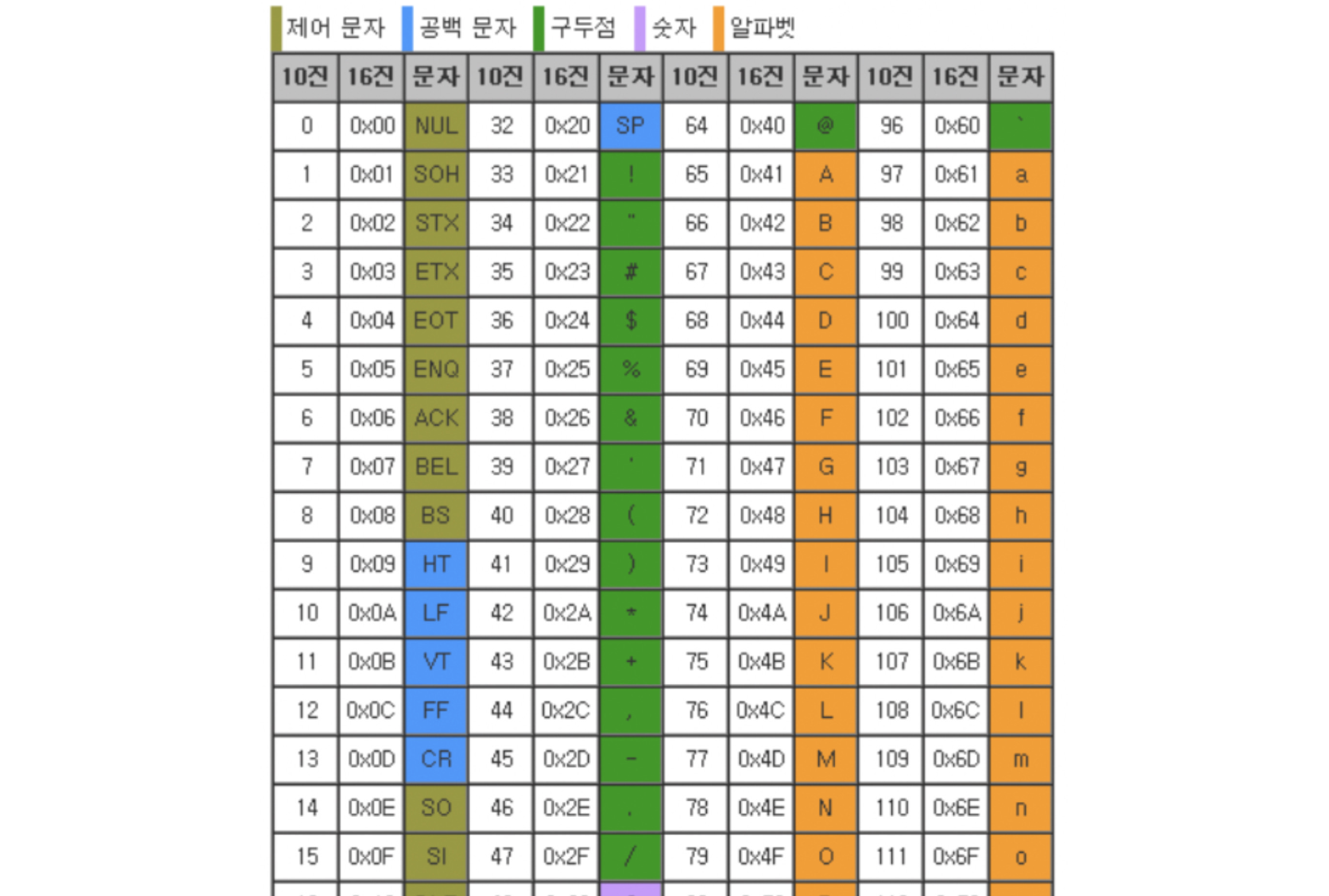
아스키 문자에 대응된 고유한 수를 아스키 코드라고 한다.
각각의 아스키 문자를 나타내기 위해 8비트를 사용한다. 그런데 1비트는 패리티 비트라고 해서, 오류 검출을 위해 사용하는 비트다. 따라서 총 7비트, 즉 128개의 문자를 표현할 수 있다.
128가지 표현은 너무 적다. 확장 아스키가 등장했지만, 그 역시 256가지 밖에 표현할 수 없었다. 게다가 아스키 코드만으로는 한글도 표현할 수 없었다. 이러한 배경에서 EUC-KR 인코딩 방식이 개발되었다.
#### 3-2-3. EUC-KR ⚙️
한글은 영어와 달리 초성+중성+종성의 조합으로 이루어진 문자다.
완성형 인코딩 방식은 완성된 하나의 글자에 고유한 코드를 부여하는 인코딩 방식이고, 조합형 인코딩 방식은 초성, 중성, 종성 각각에 코드를 부여하여 인코딩을 하는 방식이다.
EUC-KR은 완성형 인코딩 방식에 따라 초성+중성+종성이 결합된 형태의 글자에 2바이트 크기의 코드를 부여한다. 2바이트는 16비트이고, 16비트는 네 자리 십육진수로 표현할 수 있다. 글자 '가'는 십육진수 'b0a1(16)'로 인코딩 된다는 뜻이다.
EUC-KR 인코딩 방식으로 총 2,350개 정도의 한글 단어를 표현할 수 있다. 하지만 모든 한글을 표현할 수는 없었다. 마이크로소프트의 CP949가 이를 해결하기 위한 EUC-KR의 확장 버전으로서 등장했지만, 이마저도 한글 전체를 표현하기에 넉넉한 양은 아니었다.
#### 3-2-4. 유니코드와 UTF-8 ⚙️
어찌 됐건 한글을 인코딩하는 방식이 있다는 것을 확인했다. 그런데 언어별로 인코딩 방식이 전부 다르다면 개발하기 너무 어렵다. 가능한 모든 언어를 아우르는 문자 집합과 통일된 표준 인코딩 방식이 필요하지 않을까?
유니코드란, 전 세계의 모든 문자를 컴퓨터에서 일관되게 표현하고 다룰 수 있도록 설계된 산업 표준이라고 정의할 수 있다.
그런데 유니코드는 글자에 부여된 값 자체를 인코딩 된 값으로 삼지 않고, 다양한 방법으로 인코딩한다. UTF-8, UTF-16 이런 식이다.
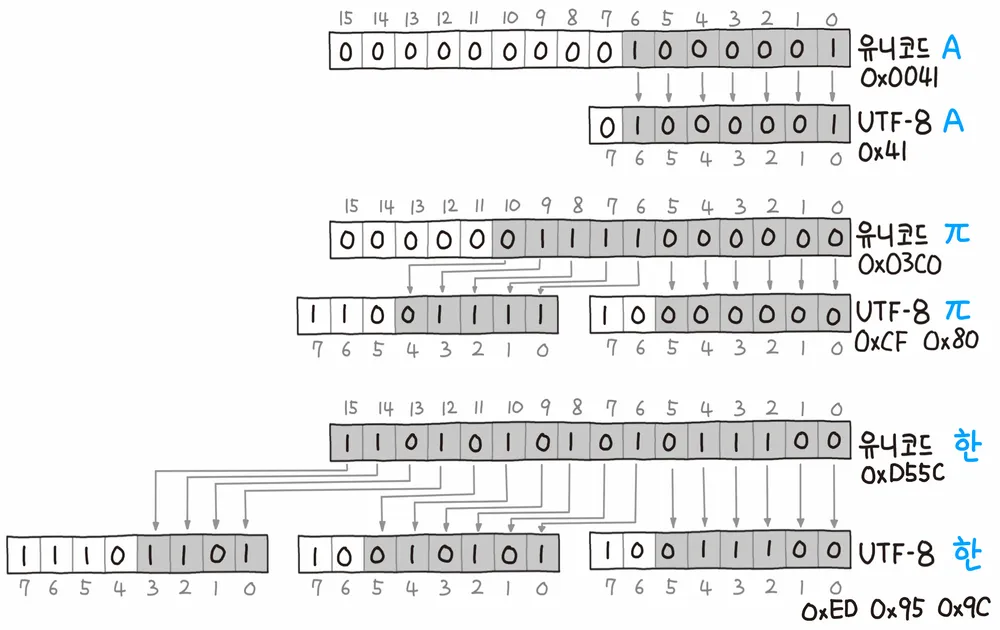
유니코드 문자에 부여된 값의 범위에 따라서 1~4바이트의 인코딩 결과를 만들어내는 것이 UTF-8 방식이라고 알고 넘어가자.
4. 명령어 ✍️
4-1. 소스 코드와 명령어 🌿
#### 4-1-1. 고급 언어 / 저급 언어 ⚙️
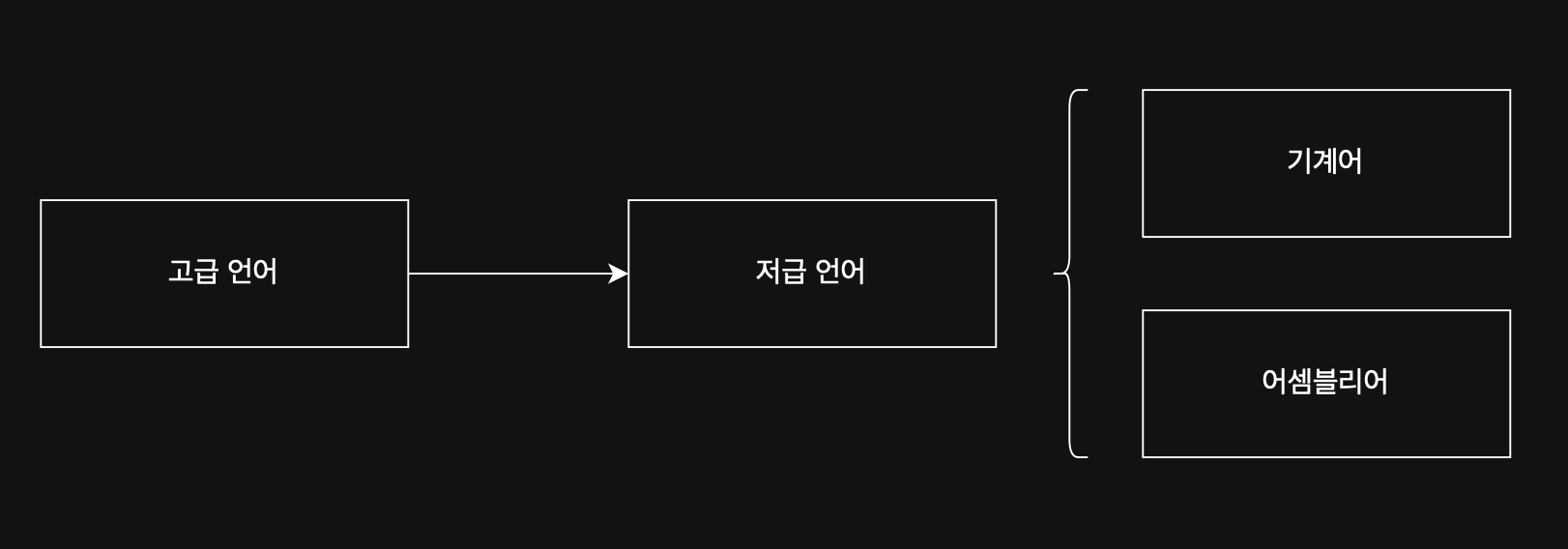
고급 언어는 사람이 이해하고 작성하기 쉽게 만들어진 언어고, 저급 언어는 컴퓨터가 직접 이해하고 실행할 수 있는 언어다.
컴퓨터가 이해하고 실행할 수 있는 언어는 오직 저급 언어뿐이다. 따라서 고급 언어로 작성된 소스 코드가 실행되려면 반드시 저급 언어로 변환되어야 한다.
#### 4-1-2. 컴파일 언어 / 인터프리터 언어 ⚙️
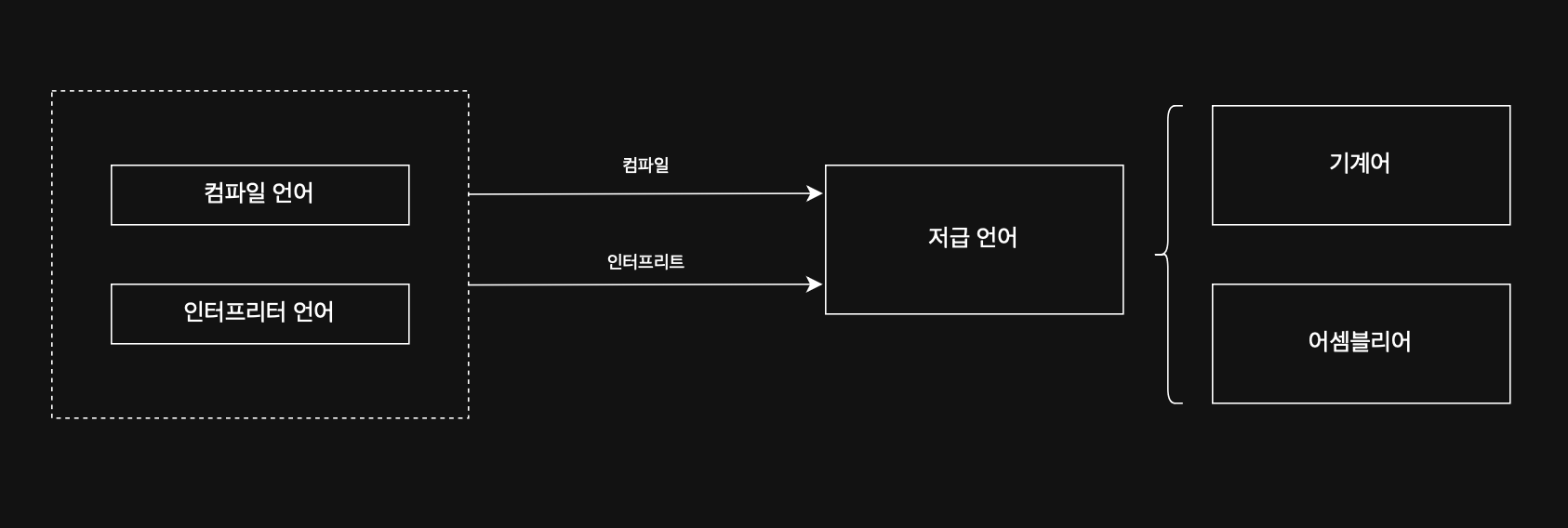
컴파일 언어는, 컴파일러에 의해 소스 코드 전체가 저급 언어로 변환된다.
인터프리터 언어는, 인터프리터에 의해 소스 코드가 한 줄씩 저급 언어로 변환되어 실행된다.
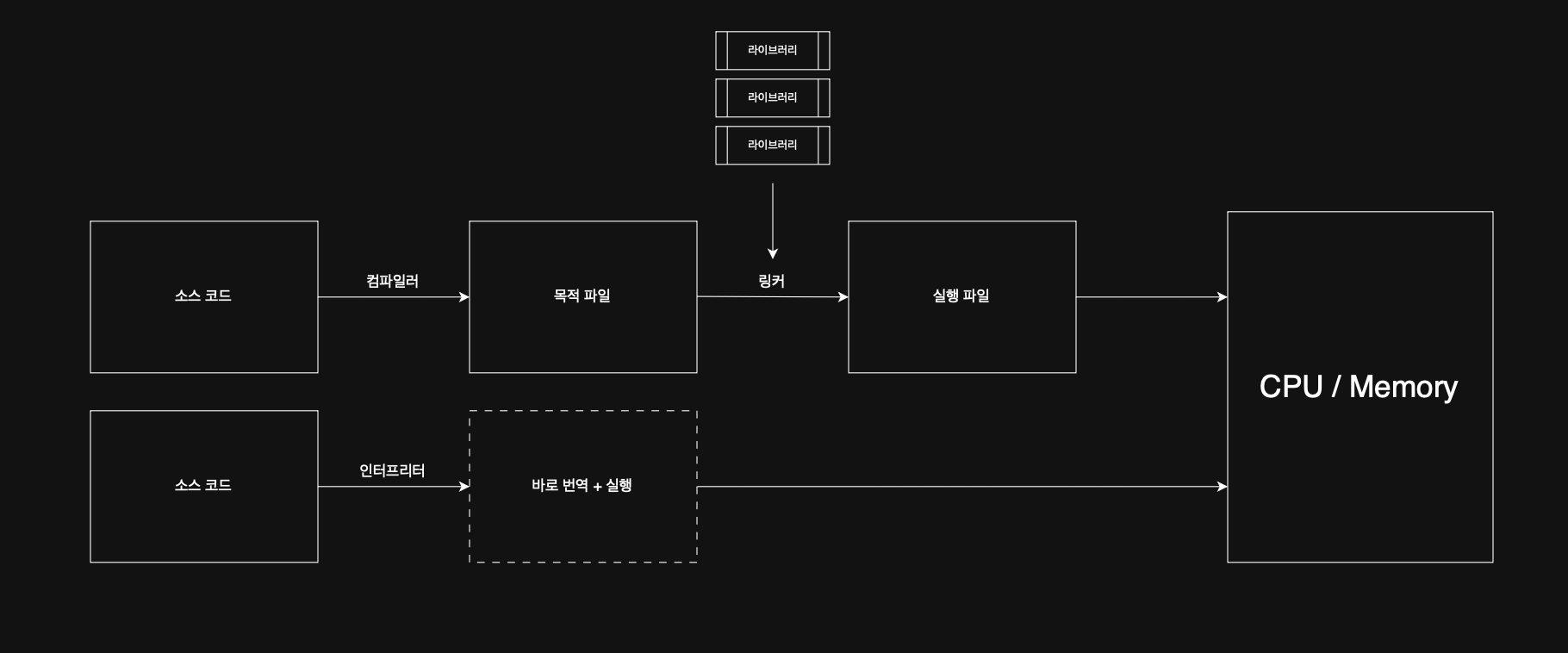
이를테면 컴파일 방식은 스페인어를 모르는 친구에게 번역본을 만들어서 건네는 방식이고, 인터프리터 방식은 옆에 앉아서 한 줄 한 줄 뜻을 알려주는 것이다.
4-2. 명령어의 구조 🌿
#### 4-2-1. 연산 코드 / 오퍼랜드 ⚙️

명령이라는 것은 대상과 동작으로 구성된다. 누구에게 무엇을 시킬지가 명령이다.
따라서 명령어는 연산 코드 필드와 오퍼랜드(=피연산자) 필드로 구성된다. 오퍼랜드 필드에는 데이터를 직접 명시하기보다는 메모리 주소나 레지스터 이름이 담긴다. 그러한 이유로 오퍼랜드 필드를 주소 필드라고 부르기도 한다.
#### 4-2-2. 주소 지정 방식 ⚙️
오퍼랜드 필드에 메모리 주소나 레지스터 주소를 담는 이유는 '명령어의 길이'에 있다. 하나의 명령어가 n비트이고 연산 코드 필드가 m비트라면, 오퍼랜드 필드의 길이는 n-m이 된다. 즉, 오퍼랜드 필드의 개수가 늘어날수록 한 개의 오퍼랜드 필드에서 표현할 수 있는 정보의 가짓수가 줄어든다.
그래서 오퍼랜드 필드에 무엇을 지정할 것인지에 따라, 지정 방식이 세분화된다.
1. 즉시 주소 지정 방식: 연산에 사용될 데이터
2. 직접 주소 지정 방식: 유효 주소(메모리 주소)
3. 간접 주소 지정 방식: 유효 주소의 주소
4. 레지스터 주소 지정 방식: 유효 주소(레지스터 이름)
5. 레지스터 간접 주소 지정 방식: 유효 주소를 저장한 레지스터
주소 지정 방식은 CPU에서의 레지스터 동작 프로세스와 엮어서 보는 것이 좋아서 특별히 도식화를 하지는 않기로 했다.
#### 4-2-3. 스택 / 큐 ⚙️
주소 지정 방식은 ``스택+큐``라는 데이터 저장 및 관리 방식과 연관된다. 주소든 값이든 어쨌든 저장하고 관리하겠다는 이야기이기에 그렇다. 구조만 간단하게 살펴보자.
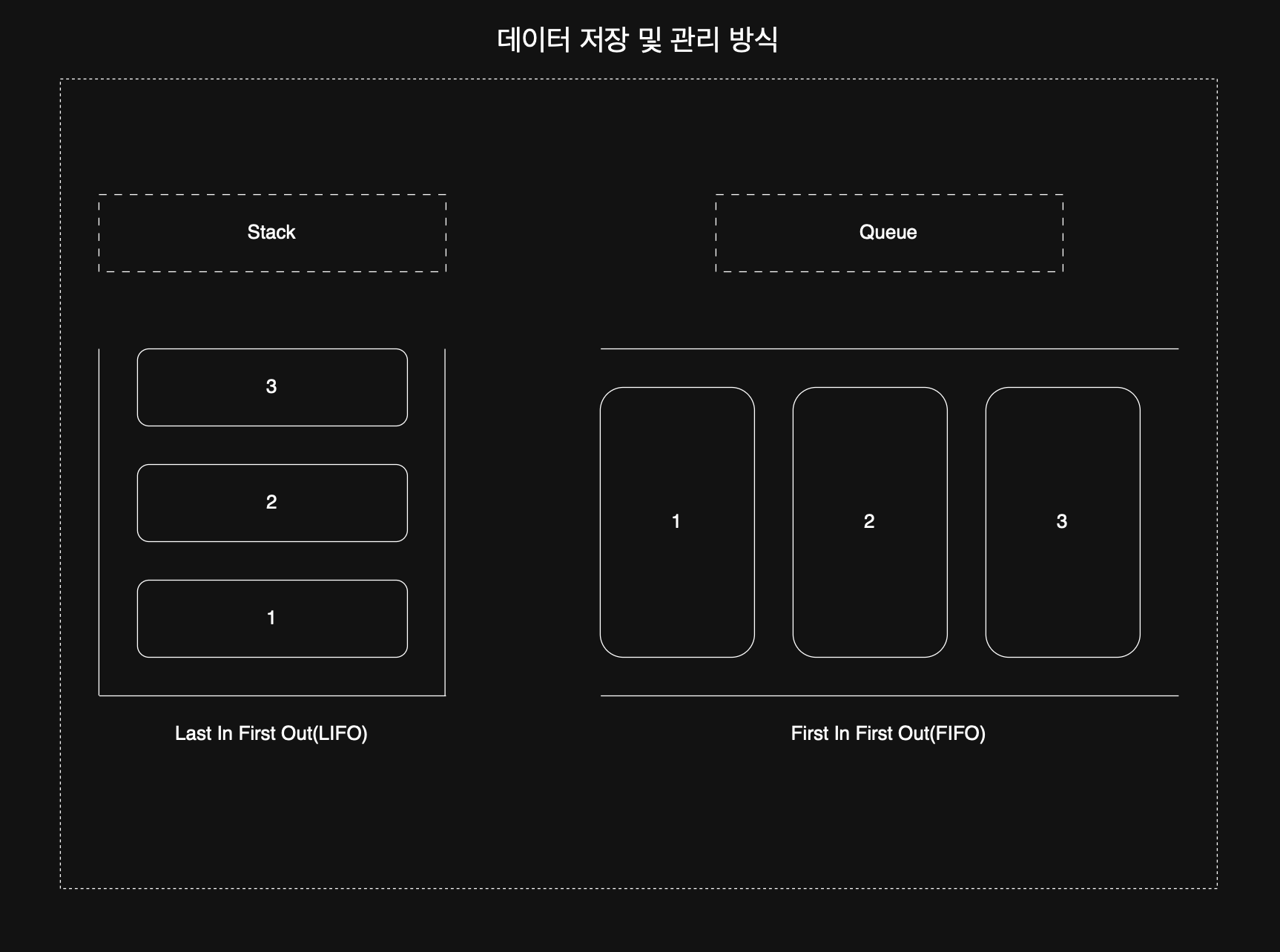
이후에는,,,
More to read
프론트엔드와 백엔드 사이
HTTP 상태 코드는 프론트엔드에서 백엔드로 보냈던 요청의 수행 결과를 의미하는 일종의 약속이며, API를 구성하는 핵심 요소 중 하나입니다. 상태 코드와 관련하여, 백엔드는 잘 모르는 프론트엔드의 슬픈 사정이 있습니다.아래는 요청이 실패했음에도, 백엔드에서 상태 코드
JWT토큰 관리 방식 톺아보기
0. 들어가며 🎯 서비스에 접근하려는 사용자가 누구인지 확인하는 과정을 사용자 인증이라고 합니다. 인증된 사용자에게 주어진 권한을 확인하는 작업은 인가라고 부릅니다. 이번 글에서는 인가는 다루지 않습니다. 사용자 인증에는 많은 방식이 있지만, 오늘은 세션 인증 방
A2AA2A / MCP 멀티 에이전트 오케스트레이션
0. 들어가며 ✍️ Google for Developers에, 레스토랑 공급망 시나리오로 엮은 6대 프로토콜(MCP, A2A, UCP, AP2, A2UI, AG-UI)에 대한 가이드가 게시된 이후, MCP와 A2A부터 구현해 보는 것이 좋을 것 같다는 생각이 들었습니