A2A / MCP 멀티 에이전트 오케스트레이션
0. 들어가며 ✍️ Google for Developers에, 레스토랑 공급망 시나리오로 엮은 6대 프로토콜(MCP, A2A, UCP, AP2, A2UI, AG-UI)에 대한 가이드가 게시된 이후, MCP와 A2A부터 구현해 보는 것이 좋을 것 같다는 생각이 들었습니
0. 들어가며 ✍️
며칠 전 Google for Developers에 레스토랑 공급망 시나리오로 엮은 6대 프로토콜에 대한 가이드가 게시된 이후, MCP와 A2A부터 구현해 보는 것이 좋을 것 같다는 생각이 들었습니다.
마이크로소프트에서 AI Specialist로 근무 중이신 서지영 님께서 10일 전 발간한, A2A x MCP 멀티 에이전트 오케스트레이션 실전이라는 책을 기반으로, A2A와 MCP 그리고 멀티 에이전트 오케스트레이션이 무엇인지에 관해 소개하겠습니다.
1. 에이전트 ✍️
1-1. 에이전트란? ✅
에이전트는 환경을 관찰하고, 관찰 결과에 따른 판단을 내리며, 판단에 따른 행동을 선택하는 존재입니다.
이제 에이전트는 다양한 데이터 소스, 복수의 API, 기업 내부 시스템, 정책 변화, 사용자 의도 등 다층적인 정보를 동시에 고려해야 하는 상황 속에서 운용되어야 합니다. 따라서 에이전트는 스크래핑이나 OS 백그라운드 자동화 모듈처럼 외부 환경 변화에 반응하는 수준을 넘어, 의사결정 단위로 기능해야 합니다.
1-2. 단일 에이전트 ✅

에이전트는 환경을 관찰하고, 관찰 결과에 따른 판단을 내리며, 판단에 따른 행동을 선택하는 존재라고 했습니다. 단 하나의 목표를 중심으로 위와 같은 흐름을 진행하는 하나의 에이전트를 단일 에이전트라고 부릅니다.
외부 입력을 받아 내부 규칙이나 지식에 기반해 추론하고, 그 결과를 출력으로 내보내는 선형적 구조를 따르게 됩니다. 오늘날의 기준에서는 제한적이라고 볼 수 있지만, 후술하게 될 멀티 에이전트 시스템이 등장하기 위한 기초를 제공했다는 점에서 큰 의미가 있습니다.
1-3. 멀티 에이전트 ✅
멀티 에이전트란 여러 개의 에이전트가 동시에 존재하면서 각자 독립적인 목표나 역할을 수행하고, 상호작용을 통해 더 큰 목적을 달성하는 구조를 의미합니다. 단순하게, 에이전트와 목표가 각각 1개가 아니라 N개라면 멀티 에이전트라고 할 수 있겠네요.

멀티 에이전트의 핵심은 분업과 병렬성에 있습니다. 분업은 일을 나눈다는 것이고, 병렬성은 나눈 일을 동시에 진행할 수 있음을 의미합니다. 가령, 하나의 에이전트는 데이터 수집을 담당하고 다른 에이전트는 데이터 분석을 수행할 수 있겠습니다. 그렇다면 "분업을 누가 지시할 것인가?"에 대한 고민이 생기는데요, 많은 경우 중앙의 오케스트레이터가 전체 과정을 조율하게 됩니다.
단, 멀티 에이전트가 항상 정답은 아닙니다. 에이전트 간의 상호작용이 늘어날수록 조율 비용이 증가하고 충돌이나 비효율이 발생할 가능성이 커집니다. 중앙 오케스트레이터가 마이크로 매니징을 할 경우, 멀티 에이전트는 단순히 병렬 실행되는 여러 단일 에이전트 집합에 머무를 수 있습니다. 아직은 잘 모르겠지만, 멀티 에이전트의 효과를 극대화하려면 에이전트 간 협력 구조와 통신 규칙을 정교하게 설계하는 것이 좋겠다는 생각이 듭니다.
1-4. MCP ✅
에이전트는 환경을 관찰하고, 관찰 결과에 따른 판단을 내리며, 판단에 따른 행동을 선택하는 존재인데요, 에이전트가 행동을 한다는 것은 도구를 사용한다는 말로 이해할 수 있습니다. 하나의 에이전트가 데이터베이스를 조회할 수도, 노션을 활용할 수도 있습니다. 에이전트가 1000가지 도구를 활용해야 한다고 가정하면, 서버에서는 1000가지 케이스에 해당하는 API 로직을 모두 개발해야 할까요?
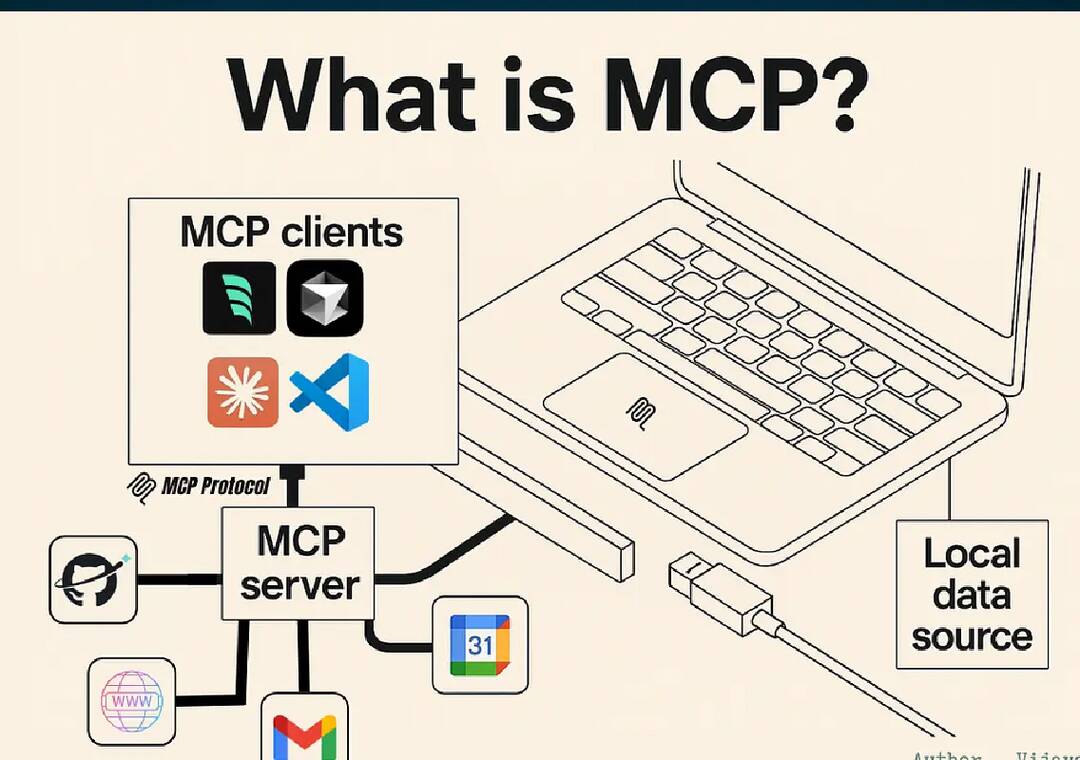
MCP는 Model Context Protocol입니다. 모델과 도구 간 소통 방식을 표준화 한 프로토콜입니다. MCP는 컨텍스트 교환이 핵심입니다. 더 정확히, 컨텍스트는 일정한 구조로, 상호작용은 동일한 방식으로 정의하는 것이 핵심입니다.
컨텍스트는 Tool manifest를 활용해 정의합니다. Tool manifest는 에이전트가 사용할 수 있는 도구들의 상세 설명서입니다. 입출력 형식을 기술하고, JSON 기반 스키마로 데이터 구조를 명확히 규정합니다.
상호작용은 원격 프로시저 호출(RPC)을 기반으로 진행합니다. Remote Procedure Call은 원격 서버 함수에 있는 함수를 마치 로컬 서버에 작성되어 있는 함수처럼 곧바로 실행하기 위해 사용하는 프로토콜입니다.
2. A2A란? ✍️
2-1. A2A 정의와 특징 ✅
A2A는, 서로 다른 기술이나 조직에서 개발한 AI 에이전트들이 표준화된 방식으로 통신하고 협업할 수 있도록 구글이 주도하여 만든 개방형 프로토콜입니다. 단순 기능 분할을 넘어 지능의 분산(Distributed Intelligence)을 실현하는 구조입니다. 다만, A2A 그 자체가 아니라 A2A 구조를 적용해야 하는 상황에 대한 깊은 고민이 필요합니다.
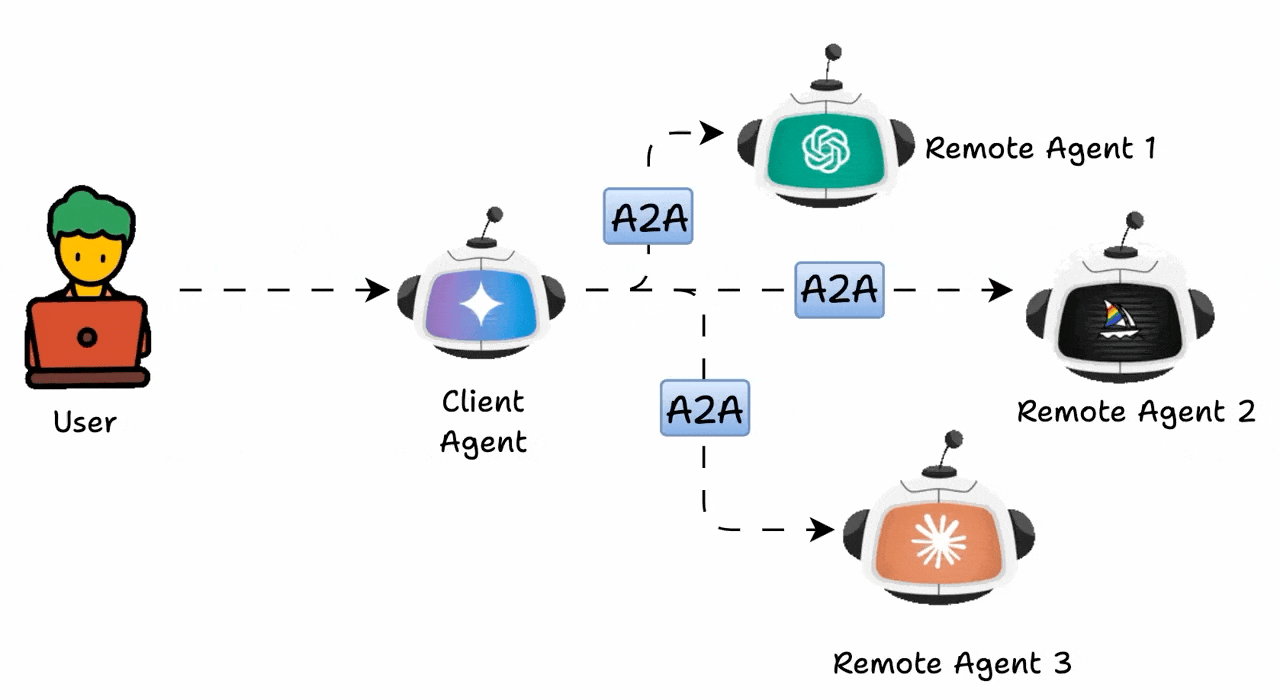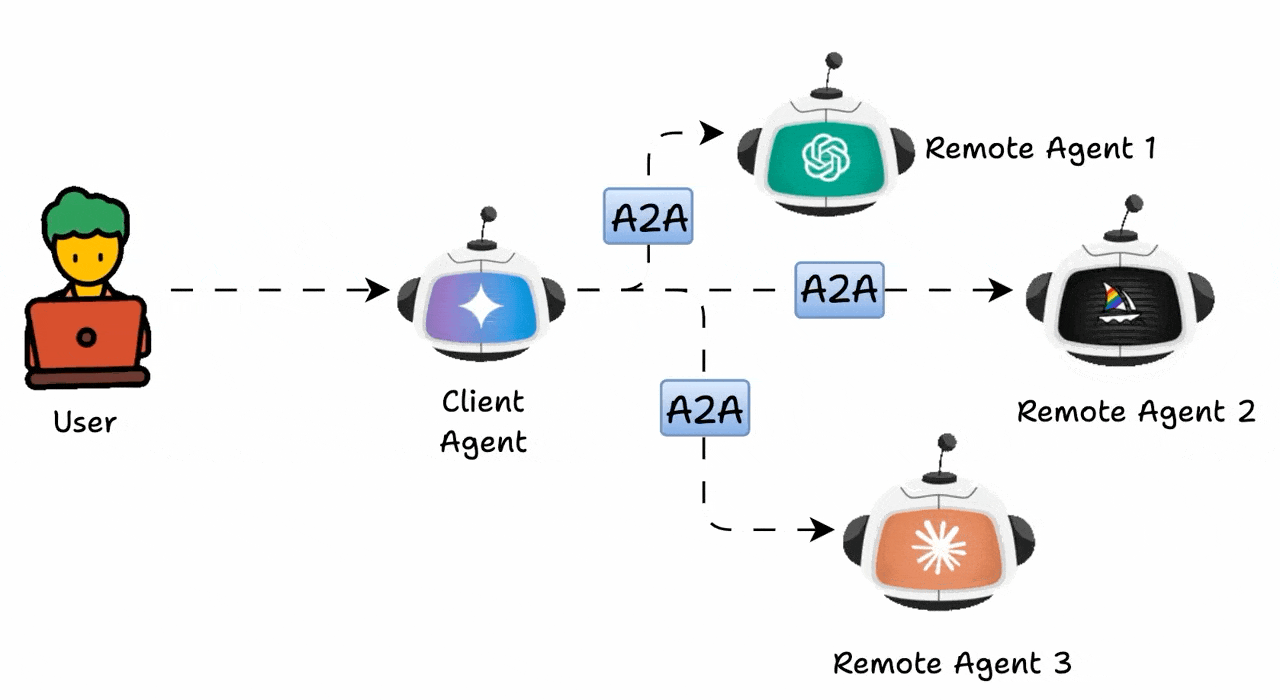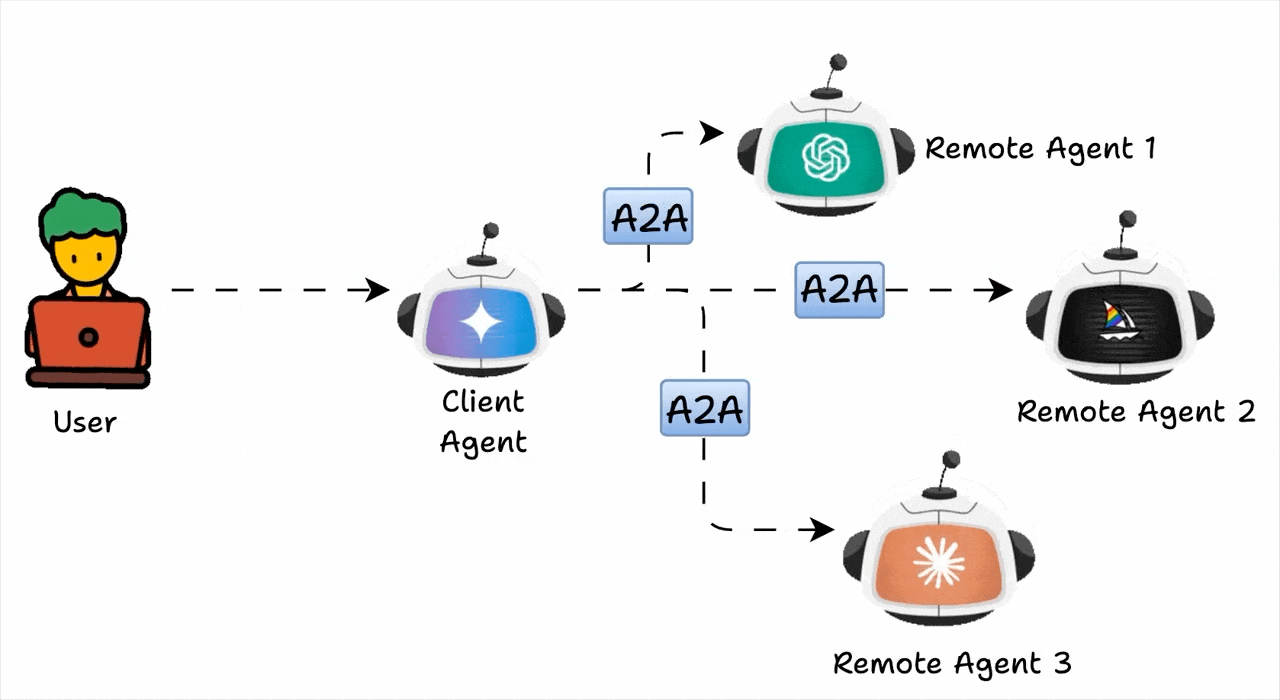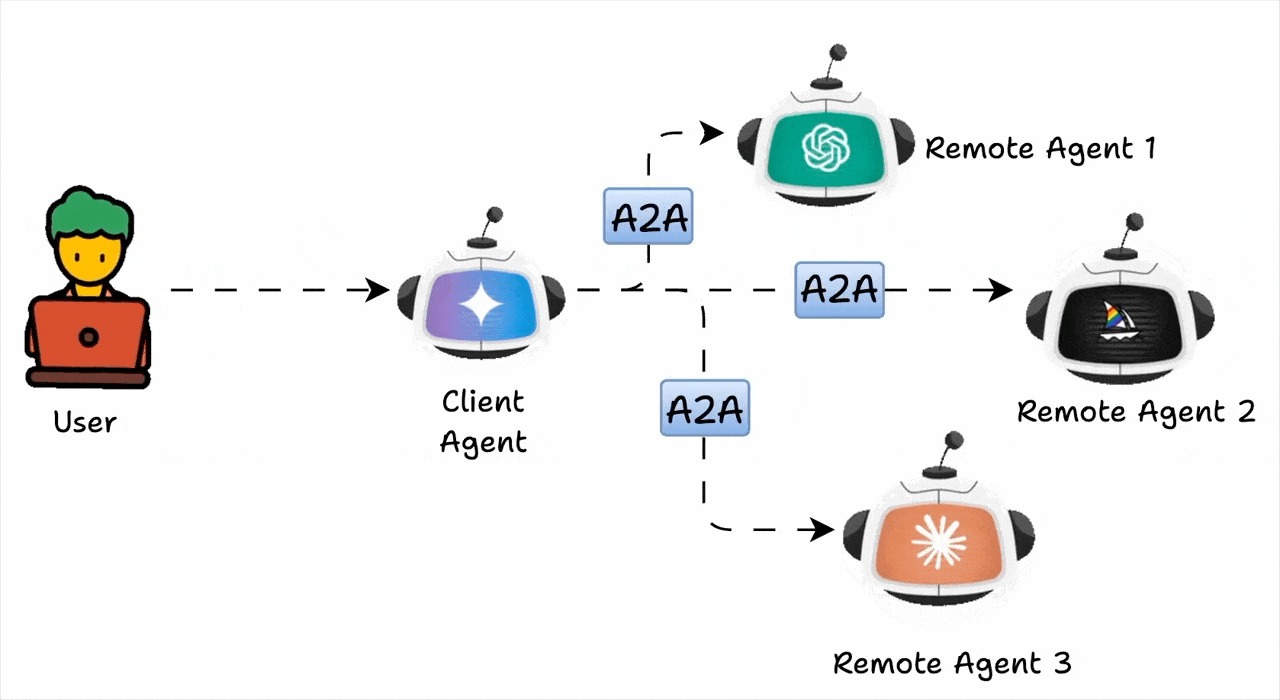
A2A 구조는 여러 클러스터와 클라우드를 넘나들며 운영되는 분산 환경, 특정 에이전트에 요청이 집중되는 환경, 실시간 대응이 필요한 환경, 멀티 도메인 협업 환경, 즉, 확장성과 유연성이 중요한 환경에서 효용이 가장 높습니다. 기존 오케스트레이터 방식과 비교하면, A2A 구조의 확장성과 유연성의 진가를 확인할 수 있습니다.
예컨대, 보험 약관 검토 프로세스를 오케스트레이터 방식으로 처리한다면, 중앙 관리자의 요구사항 추출 -> 규제 검증 -> 리스크 평가 -> 개선 제안 과정을 순차적으로 정의하게 됩니다. A2A에서는 추출 에이전트가 결과를 내면 규제 검증 에이전트가 결과를 받아 처리하고, 이어서 평가 에이전트와 개선 에이전트가 서로 협력하며 결과를 보완합니다. 과정은 유동적이지만, 그래서 더 현실적이라고 할 수 있습니다.
2-2. A2A 통신 방법 ✅
A2A 환경에서 에이전트가 서로 협력하기 위해서는 반드시 통신이 필요합니다.
그런데 여기서 말하는 통신은 단순히 정보를 주고받는 수준이 아닙니다. 서로의 기능을 호출하고, 이벤트를 기반으로 움직이며, 필요한 경우에는 비동기적으로 작업을 이어받아 실행해야 하기 때문에, 어떤 통신 방식을 선택하느냐는 A2A 시스템의 자율성, 복원력, 확장성을 결정하는 핵심 요소가 됩니다.
2-2-1. RPC 방식 🎯
앞서 언급했듯, Remote Procedure Call 방식의 본질은 원격에 있는 기능을 로컬 함수처럼 호출하는 데 있습니다.
# 분석 에이전트(서버)
def calculate_risk(data): return { "score" : 0.82 }
# 검색 에이전트(클라이언트)
response = rpc_call("http://analysis-agent/calculate_risk", data = info)
print(response["score"])만약 분석 에이전트가 calculate_risk()라는 기능을 제공하고 있다면, 검색 에이전트는 마치 내부 라이브러리를 호출하는 것처럼 해당 기능의 수행을 요청할 수 있겠습니다.
기존 프로그램에서 함수 호출을 사용하던 방식 그대로 A2A 협력을 구현할 수 있기에 프로토콜에 대한 학습 부담이 낮고, 초기 구현 속도도 빠릅니다. 에이전트 간 의사소통을 요청과 응답의 구조로 단순화하기 때문에 디버깅과 모니터링이 쉽다는 장점도 있죠.
하지만 결합도가 가장 큰 문제입니다. 호출하는 에이전트는 상대방의 API 구조, 파라미터 형식, 응답 스키마를 정확히 알고 있어야 합니다. 에이전트 수가 늘어날수록 결합도가 기하급수적으로 커지기 때문에 유지보수 난도가 매우 높아질 것이 예상됩니다.
추가적으로 RPC는 네트워크 오류에 민감합니다. 호출한 에이전트와 호출 받는 에이전트 사이에 지연이 있거나 상대 에이전트가 일시적인 장애 상태일 경우, 호출한 에이전트도 즉시 실패하게 됩니다. Retry, Timeout, Circuit Breaker 같은 안정성 패턴을 활용한다 한들, 보완적 조치에 불과합니다. 대규모 환경에서는 다른 방식과 함께 사용하는 것이 좋겠습니다.
2-2-2. gRPC 방식 🎯
gRPC는 구글이 개발한 고성능 오픈소스 RPC 프레임워크입니다. 앞서 설명한 RPC 개념을 현대적인 네트워크 환경에 맞게 재구현한 기술이라고 할 수 있습니다.
gRPC는 HTTP/2 기반의 Multiplexing, Protocol Buffers를 활용한 경량 직렬화가 기본입니다.
Multiplexing은 다수의 네트워크 연결 요청이 있을 때, 이를 동시에 처리하는 기술입니다. Protocol Buffers는 구조화된 데이터를 직렬화하는 기술입니다. 기본적으로, Multiplexing과 Protocol Buffers의 활용으로, 대규모 에이전트 네트워크에서 지연을 줄이고 처리량을 크게 높였습니다.
gRPC의 핵심 철학은 Contract-first Communication입니다. .proto 파일을 통해 서비스 이름, 메서드, 요청-응답 구조를 명확하게 정의하고, 이를 기반으로 언어에 맞는 클라이언트, 서버 코드를 자동으로 생성합니다. A2A 환경에서는 에이전트 간 인터페이스가 자주 변경되지만 .proto를 위시한 Contract-first Communication 철학 덕분에, 복잡한 생태계에서도 동일한 규칙 아래 일관된 통신을 유지할 수 있게 됩니다.
아래와 같은 분석 서비스가 있다고 가정해 보죠.
# analysis.proto
service Analysis {
rpc CalculateRisk(RiskRequest) returns (RiskResponse);
}파이썬 기반의 클라이언트 에이전트는 아래의 코드와 같이, 거의 로컬 함수를 호출하는 것처럼 원격 에이전트를 사용할 수 있습니다.
# 클라이언트 에이전트
stub = AnalysisStub(channel)
res = stub.CalculateRisk(RiskRequest(info = 'customer data'))
print(res.score)주의해야 할 점이 있습니다. gRPC는 작은 규모의 프로젝트라면 오히려 과도한 기술이 될 수 있습니다. REST API처럼 JSON 만으로 즉시 통신하는 방식이 아니라 .proto 파일을 정의, 컴파일, 언어별 코드 생성, HTTP/2 구성 등 초기 준비가 필요합니다. 더욱이, 디버깅도 상대적으로 까다롭고, 웹 브라우저가 HTTP/2 gRPC를 직접 지원하지 않기 때문에 gRPC-Web 같은 별도 Proxy가 필요한 경우도 있습니다.
2-2-3. 메시지 기반 방식 🎯
메시지 기반 통신 방식은, 여러 에이전트들이 직접 연결되지 않고도 서로 신호를 주고받으며 자율적으로 협력할 수 있도록 해주는 기술입니다. 핵심 아이디어는 간단한데요, 하나의 에이전트가 특정 사건이나 분석 결과를 메시지 형태로 발행하면, 다른 에이전트들은 자신이 구독한 메시지를 감지하고 필요한 작업을 이어서 수행합니다.
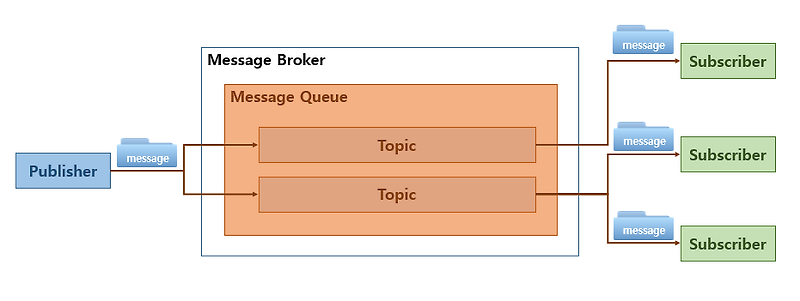
오직 메시지와 이벤트만이 협력의 단위로 작용한다는 것이 핵심입니다. 발신자와 수신자는 서로의 존재를 전혀 알 필요가 없습니다. 이러한 Loose Coupling은 새로운 에이전트를 추가하거나 기존 에이전트를 변경하더라도 전체 시스템 구조가 흔들리지 않는 높은 유연성을 제공합니다.
실제 운영 환경에서는 대부분 Kafka, RabbitMQ, Pulsar와 같은 브로커 기반 Pub/Sub 시스템으로 구현됩니다. 아래는 Kafka 기반 메시지 통신을 이용해 A2A 방식의 상호작용을 구현한 가장 기본적인 예제입니다.
producer 에이전트는 특정 event를 브로커에 발행하고, Consumer 에이전트는 자신이 구독하는 토픽에서 해당 이벤트를 감지하여 후속 작업을 자율적으로 실행합니다.
# 이벤트 발행 에이전트
from kafka import KafkaProducer
import json
producer = KafkaProducer(
bootstrap_servers = ["localhost:9092"],
value_serializer = lambda v: json.dumps(v).encode("utf-8")
)
event = {
"event_type": "analysis.completed",
"document_id": "rfp-001",
"summary": "전략 추출 완료"
}
producer.send("a2a-events", event)
producer.flush()
print("이벤트 발행 완료")아래 코드는 브로커로부터 이벤트를 구독해, 해당 이벤트가 발생했을 때 다음 단계의 작업을 시작합니다. Consumer 에이전트 역시 특정 에이전트에 의해 호출되지 않고, 이벤트를 보고 스스로 필요 여부를 판단해 행동한다는 점에서 A2A의 자율성이 드러납니다.
# 구독 에이전트
from kafka import KafkaConsumer
import json
consumer = KafkaConsumer(
"a2a-events",
bootstrap_servers = ["localhost:9092"],
value_deserializer = lambda v: json.loads(v.decode("utf-8")),
group_id = "risk-analyzer",
auto_offset_reset = "earliest"
)
for message in consumer:
event = message.value
if event["event_type"] == "analysis.completed":
print(f"[리스크 분석 에이전트] 문서: {event["document_id"]} 분석을 시작합니다.")
# 추가 분석 로직...추가적으로, 제가 생각했을 때 메시지 기반 방식에서 가장 중요한 것은 멱등성의 보장입니다. 대부분의 브로커는 at-least-once 전달 방식을 사용합니다. 즉, 동일한 메시지가 중복으로 도착할 수 있다는 것이죠. 각 에이전트는 멱등성(Idempotency)을 확보해야 합니다.
멱등성(Idempotency)이란, 동일한 작업을 여러 번 실행해도 결과는 한 번 실행했을 때와 동일하게 유지되는 성질을 의미합니다. 업계에서는 멱등성 확보를 따닥 방지라고 부른다고 하네요. 멱등성을 확보하는 방법에 대해서는 차후에 다루도록 하겠습니다.
3. A2A 구현 방법 ✍️
3-1. 설계 원칙 ✅
3-1-1. 역할 분리와 규칙 🎯
A2A 설계의 핵심은 단순히 에이전트들이 기술적으로 연결되는 데 있지 않습니다. Roles와 Rules를 명확히 정립해야 합니다. 마지 조별 과제를 준비하는 것과 같습니다. 각자의 역할과 우리 조의 규칙이 필요하겠죠.
먼저 Role Separation이 필요합니다. 가령, RFP 분석 프로젝트에서는 요구사항 추출 에이전트가 문서에서 항목을 뽑아내고, 검증 에이전트는 해당 항목을 규제와 비교하며, 리스크 평가 에이전트는 위험도를 분석하고, 보고서 작성 에이전트는 전체 결과를 정리합니다. Role Separation이 정확하게 구현되었다면 향후에 새로운 역할이 필요할 때 기존 에이전트의 기능을 변경하지 않고도 쉽게 확장할 수 있을 것입니다.
다음으로, 정확한 규칙이 필요합니다. 규칙에는 입출력 데이터 포맷, 성능 기준, 오류 처리 방식, 보안 정책 등이 포함될 수 있겠죠? 요구사항 추출 에이전트의 규칙은 다음과 같이 정의할 수 있습니다.
입력: PDF 문서 텍스트
출력: 요구사항 리스트(JSON 형식)
성능: 90% 이상의 정확도로 주요 요구사항 식별
오류 처리: 입력 문서가 손상되었을 경우 오류 코드 400 반환규칙은 사실, 기술적 명세를 넘어 거버넌스와 책임성을 강화하는 장치이기도 합니다. "개인정보가 포함된 데이터는 반드시 마스킹 한다", "승인이 필요한 변경은 자동 실행하지 않는다", "3회 연속 실패 시 안전 모드로 전환한다"와 같은 규칙은, 잘못된 의사결정이 시스템 전체로 확산되는 것을 방지하고 안전성과 신뢰성을 보장합니다.
3-1-2. 신뢰성과 오류 처리 🎯
A2A는 본질적으로 분산 환경에서 동작하기에 신뢰성과 오류 처리 메커니즘이 없다면 실무 적용은 사실상 불가능합니다. A2A의 안정적인 작동을 위해서는 어떤 점들을 고려해야 할까요?
가장 먼저 Retry 메커니즘입니다. 네트워크 지연이나 일시적 오류는 단순히 다시 시도하는 것만으로도 해결되는 경우가 많습니다. 다만, 무한 재시도는 되려 시스템을 마비시키고 장애를 키울 수 있죠. 이를 방지하기 위해 Exponential Backoff와 같은 지연 정책을 적용하여 재시도 간격을 점진적으로 늘리는 것이 바람직할 것입니다.
다음으로는 Circuit Breaker입니다. 특정 에이전트나 도구가 반복적으로 실패할 경우 자동으로 호출을 차단하고, 일정 시간 이후에만 Retry를 허용하는 방식입니다. 전기 회로에서 과부하를 방지하기 위해 차단기가 작동하는 원리와 같습니다.

대체 경로(Fallback)도 고려하는 것이 좋습니다. 특정 에이전트가 실패하더라도 시스템이 완전히 멈추지 않고 최소한의 결과를 제공할 수 있어야 합니다. 예를 들어, LLM이 답변을 생성하지 못할 경우, 간단한 키워드 매칭 기반 규칙 엔진을 활용해 기본적인 결과를 내놓는 방식입니다. 사용자는 완전한 답변을 얻지는 못하더라도 최소한의 유용한 응답을 받을 수 있습니다.
늘 그렇지만, 오류 모니터링과 알림 체계도 중요합니다. 그런데 오류는 단순히 발생 여부만 기록하는 것이 아니라 원인과 파급 효과까지 추적할 수 있어야 합니다. 특히 어떤 에이전트에서 문제가 발생했는지, 그 오류가 다른 에이전트에 어떤 영향을 끼쳤는지를 파악하는 것이 핵심입니다. 이를 위해 분산 트레이싱, 상세 로깅, 메트릭 수집 시스템이 필요하며, 이상 징후가 발견되면 즉시 알림이 전달되어야 합니다.
이외에도, PII(개인정보) 보호, 부적절한 콘텐츠 필터링, 접근 제어와 권한 관리, 인터페이스와 컨텍스트의 Versioning 등의 고려 요소들이 많지만, 이런 주제들은 차후에 필요해지면 정리하도록 하겠습니다. 처음부터 다 알 수는 없으니까요.
4. 마치며 ✍️
A2A와 MCP를 활용한 멀티 에이전트 오케스트레이션의 배경에 대해 살펴봤습니다. 저는 사실 이 정도 하면 바로 코딩으로 들어가는 편입니다. 부딪히면서 배우는 지식이 진짜 지식이니까요.
앞으로 뭘 하게 될지는 잘 모르겠습니다. 다만, A2A는 반드시 통과해야 할 주제라고 생각합니다. 금융 산업에서는 실시간 이상 거래 탐지 시스템에 A2A를 적용할 수 있을 것 같습니다. 보험 산업에서는 신상품 기획 과정에서 고객 불만과 VOC 데이터를 분석하고, 경쟁사 상품을 조사하며, 가격 모델을 산출해 종합하는 A2A 시스템을 개발할 수 있을 것 같고요. 행정 부문에서는 정책 검토나 법적 리스크 검토 과정에 A2A를 활용할 수 있을 것 같습니다.
A2A가 산업별 표준 운영 아키텍처로 자리 잡을 가능성이 매우 큽니다. 내일 더 잘하고 싶은 마음이, 여전히 최고의 동기부여인 것 같습니다. 400번째 글을 마칩니다.
More to read
프론트엔드와 백엔드 사이
HTTP 상태 코드는 프론트엔드에서 백엔드로 보냈던 요청의 수행 결과를 의미하는 일종의 약속이며, API를 구성하는 핵심 요소 중 하나입니다. 상태 코드와 관련하여, 백엔드는 잘 모르는 프론트엔드의 슬픈 사정이 있습니다.아래는 요청이 실패했음에도, 백엔드에서 상태 코드
JWT토큰 관리 방식 톺아보기
0. 들어가며 🎯 서비스에 접근하려는 사용자가 누구인지 확인하는 과정을 사용자 인증이라고 합니다. 인증된 사용자에게 주어진 권한을 확인하는 작업은 인가라고 부릅니다. 이번 글에서는 인가는 다루지 않습니다. 사용자 인증에는 많은 방식이 있지만, 오늘은 세션 인증 방
'UCP'AI Agent 핵심 프로토콜 완전 정복: MCP부터 AG-UI까지
0. 들어가며 ✍️ Reference: https://developers.googleblog.com/developers-guide-to-ai-agent-protocols/ 최근 AI Agent 개발 분야는 MCP, A2A, UCP, AP2, A2UI, AG-UI 등 수많은 약어로 인해 혼란이 가중되고 있습니다. 바로 어제, Google for Dev...